Multi-Layer Perceptron
Fast Forward: Multi-Layer Perceptrons (MLPs)
flowchart LR
classDef default fill:transparent,stroke:#333,stroke-width:1px;
classDef others fill:transparent,stroke:transparent,stroke-width:0px;
subgraph in[" "]
in1@{ shape: circle, label: " " }
in2@{ shape: circle, label: " " }
in3@{ shape: circle, label: " " }
inn@{ shape: circle, label: " " }
end
subgraph input
x1(["x<sub>1</sub>"])
x2(["x<sub>2</sub>"])
x3(["x<sub>3</sub>"])
xd(["..."]):::others
xn(["x<sub>n</sub>"])
end
subgraph hidden
h1(["h<sub>1</sub>"])
h2(["h<sub>2</sub>"])
hd(["..."]):::others
hm(["h<sub>m</sub>"])
end
subgraph output
y1(["y<sub>1</sub>"])
yd(["..."]):::others
yk(["y<sub>k</sub>"])
end
in1@{ shape: circle, label: " " } --> x1
in2@{ shape: circle, label: " " } --> x2
in3@{ shape: circle, label: " " } --> x3
inn@{ shape: circle, label: " " } --> xn
x1 -->|"w<sub>11</sub>"|h1
x1 -->|"w<sub>12</sub>"|h2
x1 -->|"w<sub>1n</sub>"|hm
x2 -->|"w<sub>21</sub>"|h1
x2 -->|"w<sub>22</sub>"|h2
x2 -->|"w<sub>2n</sub>"|hm
x3 -->|"w<sub>31</sub>"|h1
x3 -->|"w<sub>32</sub>"|h2
x3 -->|"w<sub>3n</sub>"|hm
xn -->|"w<sub>i1</sub>"|h1
xn -->|"w<sub>i2</sub>"|h2
xn -->|"w<sub>in</sub>"|hm
h1 -->|"v<sub>11</sub>"|y1
h2 -->|"v<sub>21</sub>"|y1
hm -->|"v<sub>m1</sub>"|y1
y1 --> out1@{ shape: dbl-circ, label: " " }
yk --> outn@{ shape: dbl-circ, label: " " }
style input fill:#fff,stroke:#666,stroke-width:1px
style hidden fill:#fff,stroke:#666,stroke-width:1px
style output fill:#fff,stroke:#666,stroke-width:1pxwhere:
- \( y_k \) is the output for the \( k \)-th output neuron.
- \( x_i \) are the input features.
- \( w_{ij} \) are the weights connecting the \( i \)-th input to the \( j \)-th hidden neuron.
- \( v_{jk} \) are the weights connecting the \( j \)-th hidden neuron to the \( k \)-th output neuron.
- \( b^{h}_{i} \) is the bias for the \( i \)-th hidden neuron.
- \( b^{y}_{j} \) is the bias for the \( j \)-th output neuron.
- \( m \) is the number of hidden neurons.
- \( n \) is the number of input features.
- \( f \) is the activation function applied to the weighted sums at each layer, such as sigmoid, tanh, or ReLU.
Matrix representation of the MLP architecture:
Multi-Layer Perceptron (MLP) Architecture.
| Sigmoid | Tanh | ReLU |
|---|---|---|
| \( \sigma(x) = \displaystyle \frac{1}{1 + e^{-x}} \) | \( \tanh(x) = \displaystyle \frac{e^{2x} - 1}{e^{2x} + 1} \) | \( \text{ReLU}(x) = \max(0, x) \) |
| \( \sigma'(x) = \sigma(x)(1 - \sigma(x)) \) | \( \tanh'(x) = 1 - \tanh^2(x) \) | \( \text{ReLU}'(x) = \begin{cases} 1 & \text{if } x > 0 \\ 0 & \text{if } x \leq 0 \end{cases} \) |
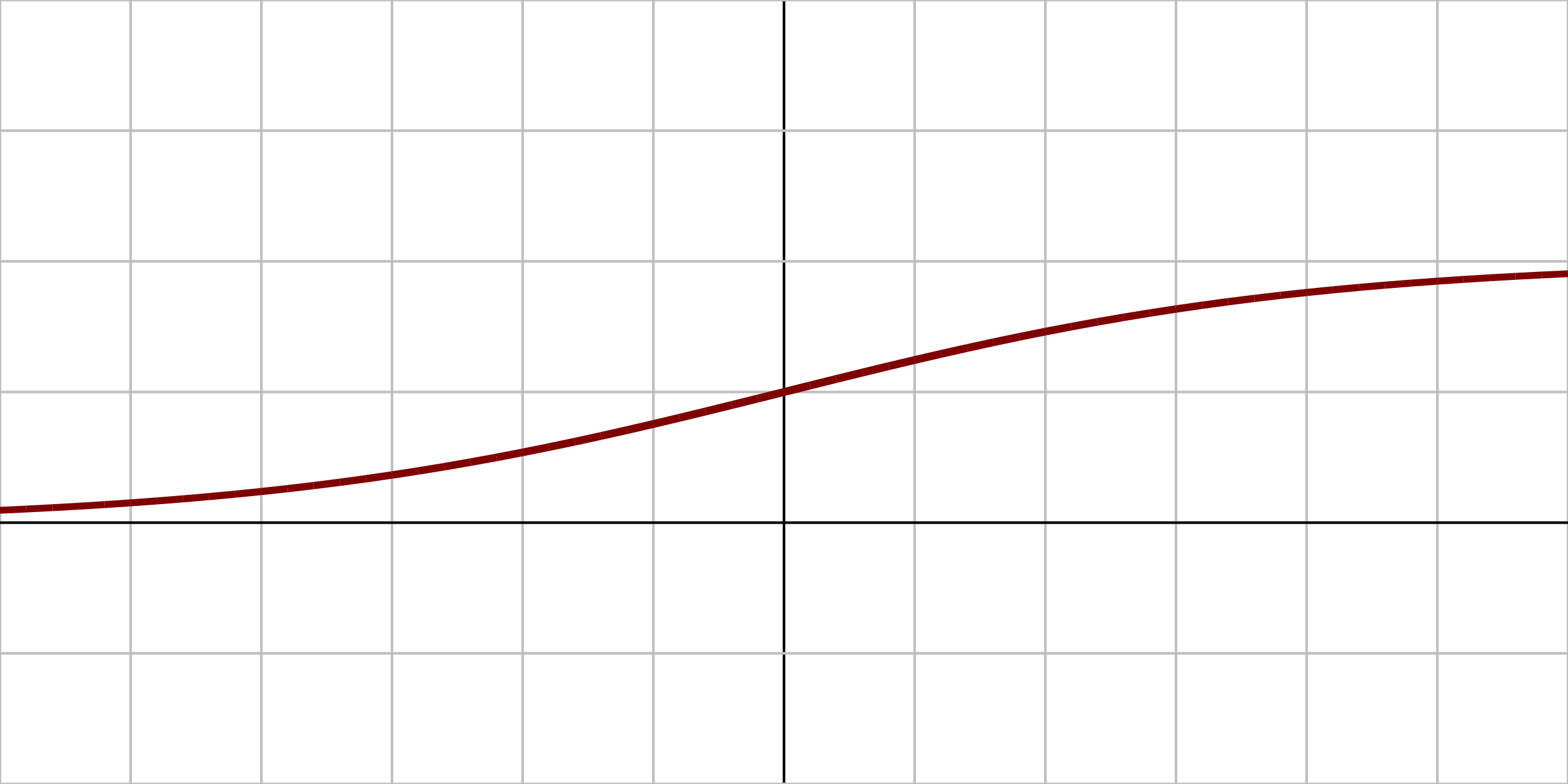 |  |  |
| Sigmoid is a smooth, S-shaped curve that outputs values between 0 and 1, making it suitable for binary classification tasks. | Tanh is a smooth curve that outputs values between -1 and 1, centering the data around zero, which can help with convergence in training. | ReLU is a piecewise linear function that outputs zero for negative inputs and the input itself for positive inputs, allowing for faster training and reducing the vanishing gradient problem. |
Backpropagation is the algorithm used to train multi-layer perceptrons (MLPs) by adjusting the weights and biases based on the error between the predicted output and the actual target. The process involves two main steps:
- Forward Pass: The input data is passed through the network, layer by layer, to compute the output. The output is compared to the target value to calculate the loss (error).
- Loss Calculation: Calculate the loss (error) between the predicted output and the actual target using a loss function, such as mean squared error or cross-entropy.
- Backward Pass: The error is propagated backward through the network to compute the gradients of the loss with respect to each weight and bias. These gradients are then used to update the weights and biases using an optimization algorithm, such as stochastic gradient descent (SGD) or Adam.
Feedforward
flowchart LR
classDef default fill:transparent,stroke:#333,stroke-width:1px;
classDef others fill:transparent,stroke:transparent,stroke-width:0px;
subgraph input
x1(["x<sub>1</sub>"])
x2(["x<sub>2</sub>"])
end
subgraph hidden
h1(["h<sub>1</sub>"])
h2(["h<sub>2</sub>"])
end
subgraph output
y(["y"])
end
in1@{ shape: circle, label: " " } --> x1
in2@{ shape: circle, label: " " } --> x2
x1 -->|"w<sub>11</sub>"|h1
x1 -->|"w<sub>12</sub>"|h2
x2 -->|"w<sub>21</sub>"|h1
x2 -->|"w<sub>22</sub>"|h2
h1 -->|"v<sub>11</sub>"|y
h2 -->|"v<sub>21</sub>"|y
y --> out1@{ shape: dbl-circ, label: " " }
style input fill:#fff,stroke:#666,stroke-width:0px
style hidden fill:#fff,stroke:#666,stroke-width:0px
style output fill:#fff,stroke:#666,stroke-width:0pxIn cannonical form, the MLP can be expressed as:
where \( f \) is the activation function, \( w_{ij} \) are the weights connecting inputs to hidden neurons, and \( v_{ij} \) are the weights connecting hidden neurons to output neurons. The biases \( b_1, b_2, \) and \( b_y \) are added to the respective layers.
Backpropagation
The backpropagation algorithm is a method used to train multi-layer perceptrons (MLPs) by minimizing the error between the predicted output and the actual target. It involves two main steps: the forward pass and the backward pass. The update of weights and biases is done using the gradients computed during the backward pass.
Training Process
Online learning is a method of training multi-layer perceptrons (MLPs) where the model is updated after each training example. This approach allows for faster convergence and can be more effective in scenarios with large datasets or when the data is not stationary.
Batch learning, on the other hand, involves updating the model after processing a batch of training examples. This method can lead to more stable updates and is often used in practice due to its efficiency in utilizing computational resources.
more:
- Limitations of Perceptrons, such as their inability to solve non-linearly separable problems.
- Introduction to Multi-Layer Perceptrons (MLPs) as an extension of the Perceptron model.
- Structure of MLPs, including input, hidden, and output layers.
- Activation functions used in MLPs, such as sigmoid, tanh, and ReLU.
- The concept of feedforward and backpropagation in MLPs.
- The role of weights and biases in MLPs and how they are adjusted during training.
- The training process of MLPs, including the use of gradient descent and backpropagation.
- The importance of loss functions in MLP training, such as mean squared error and cross-entropy.
Regularization techniques to prevent overfitting in MLPs, such as dropout and L2 regularization. https://grok.com/chat/0e1af7da-0d92-4603-84a6-99f2aa1b8686
Dropout
What it is: Dropout is a regularization technique where, during training, a random subset of neurons (or their connections) is "dropped" (set to zero) in each forward and backward pass. This prevents the network from relying too heavily on specific neurons. How it works:
During training, each neuron has a probability $ p $ (typically 0.2 to 0.5) of being dropped. This forces the network to learn redundant representations, making it more robust and less likely to memorize the training data. At test time, all neurons are active, but their weights are scaled by $ 1-p $ to account for the reduced activation during training.
Why it prevents overfitting:
Dropout acts like training an ensemble of smaller subnetworks, reducing co-dependency between neurons. It introduces noise, making the model less sensitive to specific patterns in the training data.
Practical tips:
Common dropout rates: 20–50% for hidden layers, lower (10–20%) for input layers. Use in deep networks, especially in fully connected layers or convolutional neural networks (CNNs). Avoid dropout in the output layer or when the network is small (it may hurt performance).
L2 Regularization (Weight Decay)
What it is: L2 regularization adds a penalty term to the loss function based on the magnitude of the model’s weights, discouraging large weights that can lead to complex, overfitted models. How it works:
The loss function is modified to include an L2 penalty: \(\(\text{Loss} = \text{Original Loss} + \lambda \sum w_i^2\)\) where $ w_i $ are the model’s weights, and $ \lambda $ (regularization strength) controls the penalty’s impact. During optimization, this penalty encourages smaller weights, simplifying the model.
Why it prevents overfitting:
Large weights amplify small input changes, leading to overfitting. L2 regularization constrains weights, making the model smoother and less sensitive to noise. It effectively reduces the model’s capacity to memorize training data.
Practical tips:
Common $ \lambda $: $ 10^{-5} $ to $ 10^{-2} $, tuned via cross-validation. Works well in linear models, fully connected NNs, and CNNs. Combine with other techniques (e.g., dropout) for better results.
- Optimization algorithms used in MLP training, such as stochastic gradient descent (SGD), Adam, and RMSprop.
- Evaluation metrics for MLP performance, such as accuracy, precision, recall, and F1 score.
- Common challenges in training MLPs, such as overfitting, underfitting, the vanishing gradient problem and the need for large datasets.
- Real-world applications of MLPs in various fields, including computer vision, natural language processing, and time series forecasting.
-
Applications of MLPs in various domains, including image recognition, natural language processing, and time series prediction.
-
Backpropagation: ./ann/backpropagation.md
- Regularization: ./ann/regularization.md
- Optimization: ./ann/optimization.md
- Comparison of MLPs with other neural network architectures, such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Training and Optimization
Algorithms for training ANNs involve adjusting the weights of the connections between neurons to minimize a loss function, which quantifies the difference between the predicted output and the true output. The most common optimization algorithm used in training ANNs is stochastic gradient descent (SGD), which iteratively updates the weights based on the gradient of the loss function with respect to the weights.
Additional Resources
- TensorFlow Playground is an interactive platform that allows users to visualize and experiment with neural networks. It provides a user-friendly interface to create, train, and test simple neural networks, making it an excellent tool for understanding the concepts of neural networks and their behavior. Users can adjust parameters such as the number of layers, activation functions, and learning rates to see how these changes affect the network's performance on various datasets.