10. Deep Learning
Deep learning is a subset of machine learning (which itself is part of artificial intelligence) that focuses on training artificial neural networks with multiple layers to learn and make predictions from complex data. These networks are inspired by the human brain's structure, where "neurons" process information and pass it along.
Unlike traditional machine learning algorithms (e.g., linear regression or decision trees), which often require manual feature engineering (hand-picking important data characteristics), deep learning models automatically extract features from raw data through layers of processing. This makes them powerful for tasks like image recognition, natural language processing, speech synthesis, and more.
Deep learning excels with large datasets and high computational power (e.g., GPUs), but it can be "black-box" in nature—meaning it's sometimes hard to interpret why a model makes a specific decision.
The core building block is the artificial neural network (ANN), which consists of interconnected nodes (neurons) organized into layers. Data flows from the input layer, through hidden layers (where the "deep" part comes in, with many layers stacked), to the output layer. Training involves adjusting weights (connections between neurons) using algorithms like backpropagation to minimize errors.
Key Components
A typical neural network has three main parts:
- Input Layer: The entry point where raw data (e.g., pixel values from an image) is fed into the network. It doesn't perform computations; it just passes data forward.
- Hidden Layers: The "depth" of deep learning. These are where the magic happens—multiple stacked layers that transform the data through mathematical operations. Each layer learns increasingly abstract representations (e.g., from edges in an image to full objects).
- Output Layer: The final layer that produces the prediction or classification (e.g., "cat" or "dog" in an image classifier).
Different Types of Layers
Deep learning models use various specialized layers depending on the task and architecture. Here's an overview of common layer types, grouped by their typical use. The following table summarizes their characteristics:
| Layer Type | Description | Common Use Cases | How It Works |
|---|---|---|---|
| Dense (Fully Connected) | Every neuron in this layer is connected to every neuron in the previous layer. It's the most basic type. | General-purpose networks, like simple classifiers or regressors. Often used in the final stages of more complex models. | Applies a linear transformation (weights * inputs + bias) followed by an activation function (e.g., ReLU) to introduce non-linearity. |
| Convolutional | Uses filters (kernels) to scan input data, detecting local patterns like edges or textures. Key to "convolutional neural networks" (CNNs). | Image and video processing, computer vision (e.g., object detection in photos). | Slides filters over the input, computing dot products to create feature maps. Reduces spatial dimensions while preserving important features. |
| Pooling | Downsamples the output from convolutional layers, reducing computational load and preventing overfitting. Types include max pooling (takes the maximum value) and average pooling. | Follows convolutional layers in CNNs to summarize features. | Aggregates values in small regions (e.g., 2x2 grid) into a single value, making the model more robust to variations like translations. |
| Recurrent (e.g., RNN, LSTM, GRU) | Handles sequential data by maintaining a "memory" of previous inputs via loops. LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit) are advanced variants that address vanishing gradient issues. | Time-series forecasting, natural language processing (e.g., machine translation), speech recognition. | Processes inputs one step at a time, using hidden states to carry information forward. Good for sequences but can struggle with long dependencies. |
| Embedding | Converts categorical data (e.g., words) into dense vectors of fixed size, capturing semantic relationships. | NLP tasks like word embeddings (e.g., Word2Vec). Often the first layer in text-based models. | Maps high-dimensional sparse data (e.g., one-hot encoded words) to lower-dimensional continuous space. |
| Attention (used in Transformers) | Allows the model to focus on relevant parts of the input dynamically, weighing their importance. Self-attention computes relationships between all elements. | Modern NLP (e.g., GPT models), machine translation, and even vision tasks. | Uses queries, keys, and values to compute attention scores, enabling parallel processing of sequences (unlike RNNs). |
| Normalization (e.g., Batch Normalization, Layer Normalization) | Stabilizes training by normalizing activations within a layer, reducing internal covariate shift. | Almost all deep networks to speed up training and improve performance. | Adjusts and scales activations (e.g., mean to 0, variance to 1) across mini-batches or individual layers. |
| Dropout | Randomly "drops out" (ignores) a fraction of neurons during training to prevent overfitting. | Regularization in any network, especially dense or convolutional ones. | Temporarily removes connections, forcing the network to learn redundant representations. Inactive during inference. |
| Flatten | Converts multi-dimensional data (e.g., from convolutional layers) into a 1D vector for dense layers. | Transitioning from feature extraction (CNN) to classification. | Reshapes tensors without changing values, e.g., turning a 2D feature map into a flat array. |
| Activation | Applies a non-linear function to the output of other layers (though often built into them). Common ones: ReLU (Rectified Linear Unit), Sigmoid, Tanh, Softmax. | Everywhere, to add non-linearity and control output ranges (e.g., Softmax for probabilities). | Transforms linear outputs; e.g., ReLU sets negative values to 0 for faster training. |
Common Deep Learning Architectures
These layers are combined into architectures tailored to specific problems:
- Feedforward Neural Networks (FNN): Basic stack of dense layers for simple tasks.
- Convolutional Neural Networks (CNN): Convolutional + pooling layers for spatial data like images (e.g., ResNet, VGG).
- Recurrent Neural Networks (RNN): Recurrent layers for sequences (e.g., LSTM for text generation).
- Transformers: Attention layers for handling long-range dependencies (e.g., BERT for NLP, Vision Transformers for images).
- Autoencoders: Encoder (convolutional/dense) + decoder layers for unsupervised learning like denoising.
- Generative Adversarial Networks (GANs): Combines generator and discriminator networks (often convolutional) for generating realistic data.
Forward and Backward Pass for Each Layer
The forward pass computes the output of each layer given the input, while the backward pass computes gradients for learning.
Backpropagation computes the gradient of the loss with respect to the layer's inputs and parameters (e.g., weights, biases) to update them via optimizers like gradient descent. Assume a scalar loss \( L \), and upstream gradient \( \displaystyle \frac{\partial L}{\partial y} \) (where \( y \) is the layer's output) is provided from the next layer.
A. Dense (Fully Connected)
Every neuron in this layer is connected to every neuron in the previous layer. It's the most basic type. General-purpose networks, like simple classifiers or regressors. Often used in the final stages of more complex models.

A sample of a small fully-connected layer with four input and eight output neurons. Source: Linear/Fully-Connected Layers User's Guide
Parameters:
-
x: Input vector.
W: Weight matrix.
b: Bias vector.
-
\( x = [2, 3] \)
\( W = \begin{bmatrix} 1 & 2 \\ 0 & -1 \end{bmatrix} \)
\( b = [1, -1] \)
Forward Pass:
-
\( y = Wx + b \),
then apply activation (e.g., ReLU: \( y = \max(0, y) \)).
-
\( y = [9, -4] \),
ReLU: [9, 0].
Backward Pass:
-
-
Gradient w.r.t. input:
\( \displaystyle \frac{\partial L}{\partial x} = W^T \cdot \frac{\partial L}{\partial y'} \)
where \( y' \) is post-activation,
and \( \displaystyle \frac{\partial L}{\partial y'} \) is adjusted for activation,
e.g., for ReLU: 1 if \( y > 0 \), else 0).
-
Gradient w.r.t. weights:
\( \displaystyle \frac{\partial L}{\partial W} = \frac{\partial L}{\partial y'} \cdot x^T \).
-
Gradient w.r.t. bias:
\( \displaystyle \frac{\partial L}{\partial b} = \sum \frac{\partial L}{\partial y'} \).
-
-
Assume loss gradient \( \frac{\partial L}{\partial y'} = [0.5, -0.2] \) (post-ReLU). For ReLU: mask = [1, 0], so \( \frac{\partial L}{\partial y} = [0.5, 0] \).
-
\( \begin{align*} \displaystyle \frac{\partial L}{\partial x} &= W^T \cdot [0.5, 0] \\ & = \begin{bmatrix} 1 & 0 \\ 2 & -1 \end{bmatrix} \begin{bmatrix} 0.5 \\ 0 \end{bmatrix} \\ & = [0.5, 1.0] \end{align*} \).
-
\( \begin{align*} \displaystyle \frac{\partial L}{\partial W} &= [0.5, 0]^T \cdot [2, 3] \\ & = \begin{bmatrix} 1 & 1.5 \\ 0 & 0 \end{bmatrix} \end{align*} \).
-
\( \displaystyle \frac{\partial L}{\partial b} = [0.5, 0] \).
-
Implementation:
import numpy as np
def dense_forward(x, W, b):
y_linear = np.dot(W, x) + b
y = np.maximum(0, y_linear) # ReLU
return y, y_linear # Cache linear for backprop
def dense_backward(dy_post_act, x, W, y_linear):
# dy_post_act: ∂L/∂y (post-ReLU)
dy_linear = dy_post_act * (y_linear > 0) # ReLU derivative
dx = np.dot(W.T, dy_linear)
dW = np.outer(dy_linear, x)
db = dy_linear
return dx, dW, db
# Example
x = np.array([2, 3])
W = np.array([[1, 2], [0, -1]])
b = np.array([1, -1])
y, y_linear = dense_forward(x, W, b)
dy_post_act = np.array([0.5, -0.2])
dx, dW, db = dense_backward(dy_post_act, x, W, y_linear)
print("Forward y:", y) # [9, 0]
print("dx:", dx) # [0.5, 1.0]
print("dW:", dW) # [[1, 1.5], [0, 0]]
print("db:", db) # [0.5, 0]B. Convolutional
Uses filters (kernels) to scan input data, detecting local patterns like edges or textures. Key to "convolutional neural networks" (CNNs). Image and video processing, computer vision (e.g., object detection in photos). Slides filters over the input, computing dot products to create feature maps. Reduces spatial dimensions while preserving important features.

Convolution of an image with an edge detector convolution kernel. Sources: Deep Learning in a Nutshell: Core Concepts
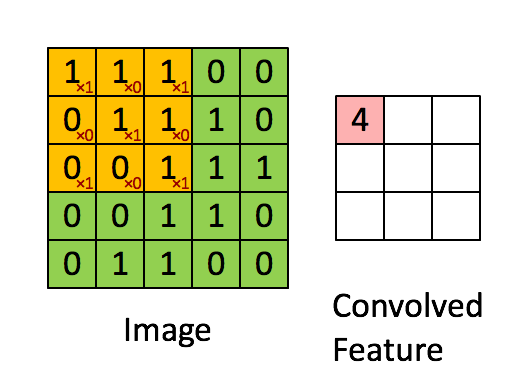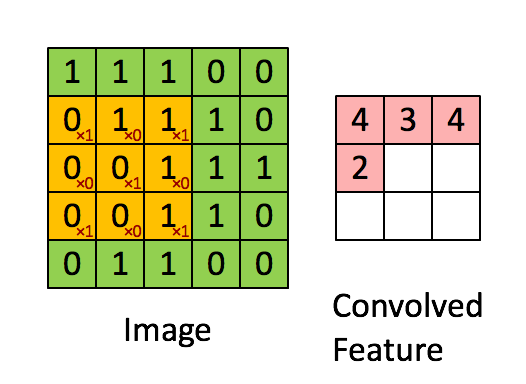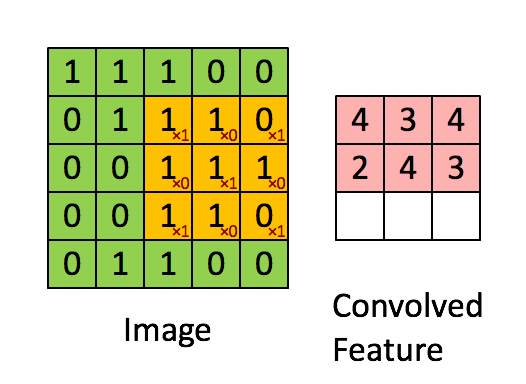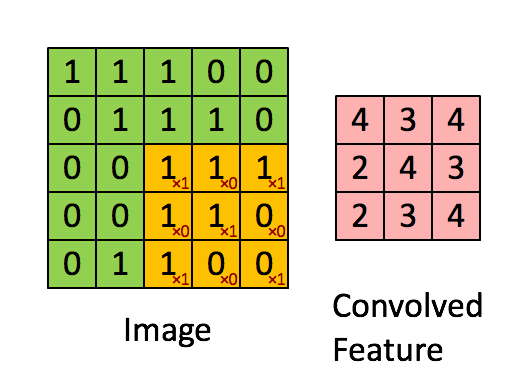
Calculating convolution by sliding image patches over the entire image. One image patch (yellow) of the original image (green) is multiplied by the kernel (red numbers in the yellow patch), and its sum is written to one feature map pixel (red cell in convolved feature). Image source: Deep Learning in a Nutshell: Core Concepts
Parameters:
-
X: Input matrix (e.g., image).
K: Convolution kernel (filter).
b: Bias term.
-
(2D, stride=1, no padding):
\( X = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix} \)
\( K = \begin{bmatrix} 1 & 0 \\ -1 & 1 \end{bmatrix} \)
\( b=1 \)
Forward Pass:
-
Convolution:
\( \displaystyle Y[i,j] = \sum_{m,n} X[i+m, j+n] \cdot K[m,n] + b \).
-
Convolution:
\( \begin{bmatrix} \begin{array}{ll} =& 1 \times 1 + 2 \times 0 \\ &+ 4 \times (-1) + 5 \times 1 \\ &+ 1 \end{array} & \begin{array}{ll} =& 2 \times 1 + 3 \times 0 \\ &+ 5 \times (-1) + 6 \times 1 \\ &+ 1 \end{array} \\ \begin{array}{ll} =& 4 \times 1 + 5 \times 0 \\ &+ 7 \times (-1) + 8 \times 1 \\ &+ 1 \end{array} & \begin{array}{ll} =& 5 \times 1 + 6 \times 0 \\ &+ 8 \times (-1) + 9 \times 1 \\ &+ 1 \end{array} \end{bmatrix} \)
\( Y = \begin{bmatrix} 3 & 3 \\ -1 & -1 \end{bmatrix} \)
Backward Pass:
-
-
Gradient w.r.t. input:
Convolve upstream gradient \( \displaystyle \frac{\partial L}{\partial Y} \) with rotated kernel (full convolution).
-
Gradient w.r.t. kernel:
Convolve input \( X \) with \( \displaystyle \frac{\partial L}{\partial Y} \).
-
Gradient w.r.t. bias:
Sum of \( \displaystyle \frac{\partial L}{\partial Y} \).
-
-
\( \displaystyle \frac{\partial L}{\partial Y} = \begin{bmatrix} 0.5 & -0.5 \\ 1 & 0 \end{bmatrix} \).
-
\( \displaystyle \frac{\partial L}{\partial X} \):
Full conv with rotated K (\( \begin{bmatrix} 1 & -1 \\ 0 & 1 \end{bmatrix} \)) and padded \( dY \), approx. \( \begin{bmatrix} 0.5 & -0.5 & -0.5 \\ 0 & 1.5 & 0 \\ 1 & 0 & 0 \end{bmatrix} \) (simplified calc).
-
\( \displaystyle \frac{\partial L}{\partial K} = \) Conv X with dY:
\( \begin{bmatrix} 0.5*1 + (-0.5)*2 + 1*4 + 0*5 \\ \ldots \end{bmatrix} \)
(detailed in code).
-
\( \displaystyle \frac{\partial L}{\partial b} = 0.5 -0.5 +1 +0 = 1 \).
-
Implementation:
import numpy as np
from scipy.signal import correlate2d, convolve2d
def conv_forward(X, K, b):
Y = correlate2d(X, K, mode='valid') + b # SciPy correlate for conv
return Y, X # Cache X
def conv_backward(dY, X, K):
# Rotate kernel 180 degrees for full conv
K_rot = np.rot90(K, 2)
# Pad dY to match X shape for dx
pad_h, pad_w = K.shape[0]-1, K.shape[1]-1
dY_padded = np.pad(dY, ((pad_h//2, pad_h-pad_h//2), (pad_w//2, pad_w-pad_w//2)))
dX = convolve2d(dY_padded, K_rot, mode='valid')
dK = correlate2d(X, dY, mode='valid')
db = np.sum(dY)
return dX, dK, db
# Example
X = np.array([[1,2,3],[4,5,6],[7,8,9]])
K = np.array([[1,0],[-1,1]])
b = 1
Y, _ = conv_forward(X, K, b)
dY = np.array([[0.5, -0.5],[1, 0]])
dX, dK, db = conv_backward(dY, X, K)
print("Forward Y:\n", Y)
print("dX:\n", dX)
print("dK:\n", dK)
print("db:", db)C. Pooling (Max Pooling)
Downsamples the output from convolutional layers, reducing computational load and preventing overfitting. Types include max pooling (takes the maximum value) and average pooling. Follows convolutional layers in CNNs to summarize features. Aggregates values in small regions (e.g., 2x2 grid) into a single value, making the model more robust to variations like translations.
Forward Pass:
-
\( Y[i,j] = \max(X[i:i+k, j:j+k]) \) for pool size \( k \).
-
\( X = \begin{bmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \\ 13 & 14 & 15 & 16 \end{bmatrix} \), pool=2, stride=2,
\( Y = \begin{bmatrix} 6 & 8 \\ 14 & 16 \end{bmatrix} \).
- Max positions: e.g., 6 from X[1,1]=6, etc.
Backward Pass:
-
Distribute upstream gradient \( \displaystyle \frac{\partial L}{\partial Y} \) to the max position in each window; 0 elsewhere.
-
\( \displaystyle \frac{\partial L}{\partial Y} = \begin{bmatrix} 0.5 & -0.5 \\ 1 & 0 \end{bmatrix} \).
-
\( \displaystyle \frac{\partial L}{\partial X} \):
- 0.5 to pos of 6 (1,1),
- -0.5 to pos of 8 (1,3),
- 1 to pos of 14 (3,1),
- 0 to pos of 16 (3,3).
- Other positions 0.
-
Implementation:
import numpy as np
def max_pool_forward(X, pool_size=2, stride=2):
H, W = X.shape
out_H, out_W = H // stride, W // stride
Y = np.zeros((out_H, out_W))
max_idx = np.zeros_like(X, dtype=bool) # For backprop
for i in range(0, H, stride):
for j in range(0, W, stride):
slice = X[i:i+pool_size, j:j+pool_size]
max_val = np.max(slice)
Y[i//stride, j//stride] = max_val
max_idx[i:i+pool_size, j:j+pool_size] = (slice == max_val)
return Y, max_idx
def max_pool_backward(dY, max_idx, pool_size=2, stride=2):
dX = np.zeros_like(max_idx, dtype=float)
for i in range(dY.shape[0]):
for j in range(dY.shape[1]):
dX[i*stride:i*stride+pool_size, j*stride:j*stride+pool_size] = dY[i,j] * max_idx[i*stride:i*stride+pool_size, j*stride:j*stride+pool_size]
return dX
# Example
X = np.arange(1,17).reshape(4,4)
Y, max_idx = max_pool_forward(X)
dY = np.array([[0.5, -0.5],[1, 0]])
dX = max_pool_backward(dY, max_idx)
print("Forward Y:\n", Y)
print("dX:\n", dX)D. Recurrent (LSTM)
Recurrent Neural Networks (RNNs) are powerful for sequence data. Long Short-Term Memory (LSTM) networks are a type of RNN designed to capture long-term dependencies and mitigate issues like vanishing gradients.
Parameters:
-
(Simplified to hidden size=1 for clarity):
-
Inputs:
\( x_t = [0.5] \),
\( h_{t-1} = [0.1] \),
\( C_{t-1} = [0.2] \)
-
Weights:
\( W_f = [[0.5, 0.5]] \),
\( W_i = [[0.4, 0.4]] \),
\( W_C = [[0.3, 0.3]] \),
\( W_o = [[0.2, 0.2]] \)
-
Biases: \( b_f = b_i = b_C = b_o = [0.0] \)
-
Forward Pass:
-
- Concatenate: \( \text{concat} = [h_{t-1}, x_t] \)
- Forget gate: \( f_t = \sigma(W_f \cdot \text{concat} + b_f) \)
- Input gate: \( i_t = \sigma(W_i \cdot \text{concat} + b_i) \)
- Cell candidate: \( \tilde{C}_t = \tanh(W_C \cdot \text{concat} + b_C) \)
- Cell state: \( C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t \)
- Output gate: \( o_t = \sigma(W_o \cdot \text{concat} + b_o) \)
- Hidden state: \( h_t = o_t \cdot \tanh(C_t) \)
-
- concat = [0.1, 0.5]
- \( f_t = \sigma(0.3) \approx 0.5744 \)
- \( i_t = \sigma(0.24) \approx 0.5597 \)
- \( \tilde{C}_t = \tanh(0.18) \approx 0.1785 \)
- \( C_t \approx 0.5744 \cdot 0.2 + 0.5597 \cdot 0.1785 \approx 0.2146 \)
- \( o_t = \sigma(0.12) \approx 0.5300 \)
- \( h_t \approx 0.5300 \cdot \tanh(0.2146) \approx 0.1120 \)
Backward Pass:
-
Gradients are computed via chain rule:
- \( dC_t = dh_t \cdot o_t \cdot (1 - \tanh^2(C_t)) + dC_{next} \) (dC_next from future timestep)
- \( do_t = dh_t \cdot \tanh(C_t) \cdot \sigma'(o_t) \)
- \( d\tilde{C}_t = dC_t \cdot i_t \cdot (1 - \tilde{C}_t^2) \)
- \( di_t = dC_t \cdot \tilde{C}_t \cdot \sigma'(i_t) \)
- \( df_t = dC_t \cdot C_{t-1} \cdot \sigma'(f_t) \)
- \( dC_{prev} = dC_t \cdot f_t \)
- Then, backpropagate to concat: \( d\text{concat} = W_o^T \cdot do_t + W_C^T \cdot d\tilde{C}_t + W_i^T \cdot di_t + W_f^T \cdot df_t \)
- Split \( d\text{concat} \) into \( dh_{prev} \) and \( dx_t \)
- Parameter gradients: \( dW_f = df_t \cdot \text{concat}^T \), \( db_f = df_t \), and similarly for others.
-
(Assume upstream: \( dh_t = [0.1] \), \( dC_t = [0.05] \) from next timestep):
- \( dC_t \approx 0.1 \cdot 0.5300 \cdot (1 - \tanh^2(0.2146)) + 0.05 \approx 0.1028 + 0.05 = 0.1528 \) (detailed steps in code output)
- Resulting gradients match the executed values below (e.g., \( dx_t \approx [0.0216] \), etc.).
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def dsigmoid(y):
return y * (1 - y)
def tanh(x):
return np.tanh(x)
def dtanh(y):
return 1 - y**2
# Forward pass
def lstm_forward(x_t, h_prev, C_prev, W_f, W_i, W_C, W_o, b_f, b_i, b_C, b_o):
concat = np.concatenate((h_prev, x_t), axis=0)
f_t = sigmoid(np.dot(W_f, concat) + b_f)
i_t = sigmoid(np.dot(W_i, concat) + b_i)
C_tilde = tanh(np.dot(W_C, concat) + b_C)
C_t = f_t * C_prev + i_t * C_tilde
o_t = sigmoid(np.dot(W_o, concat) + b_o)
h_t = o_t * tanh(C_t)
cache = (concat, f_t, i_t, C_tilde, o_t, C_t)
return h_t, C_t, cache
# Backward pass
def lstm_backward(dh_next, dC_next, cache, W_f, W_i, W_C, W_o):
concat, f_t, i_t, C_tilde, o_t, C_t = cache
# Derivatives
dC_t = dh_next * o_t * dtanh(tanh(C_t)) + dC_next
do_t = dh_next * tanh(C_t) * dsigmoid(o_t)
dC_tilde = dC_t * i_t * dtanh(C_tilde)
di_t = dC_t * C_tilde * dsigmoid(i_t)
df_t = dC_t * C_prev * dsigmoid(f_t)
dC_prev = dC_t * f_t
# Gradients for gates
dconcat_o = np.dot(W_o.T, do_t)
dconcat_C = np.dot(W_C.T, dC_tilde)
dconcat_i = np.dot(W_i.T, di_t)
dconcat_f = np.dot(W_f.T, df_t)
dconcat = dconcat_f + dconcat_i + dconcat_C + dconcat_o
# Split for h_prev and x_t
hidden_size = h_prev.shape[0]
dh_prev = dconcat[:hidden_size]
dx_t = dconcat[hidden_size:]
# Parameter gradients
dW_f = np.outer(df_t, concat)
db_f = df_t
dW_i = np.outer(di_t, concat)
db_i = di_t
dW_C = np.outer(dC_tilde, concat)
db_C = dC_tilde
dW_o = np.outer(do_t, concat)
db_o = do_t
return dx_t, dh_prev, dC_prev, dW_f, db_f, dW_i, db_i, dW_C, db_C, dW_o, db_o
# Numerical example (hidden size = 1)
x_t = np.array([0.5])
h_prev = np.array([0.1])
C_prev = np.array([0.2])
W_f = np.array([[0.5, 0.5]])
W_i = np.array([[0.4, 0.4]])
W_C = np.array([[0.3, 0.3]])
W_o = np.array([[0.2, 0.2]])
b_f = np.array([0.0])
b_i = np.array([0.0])
b_C = np.array([0.0])
b_o = np.array([0.0])
# Forward
h_t, C_t, cache = lstm_forward(x_t, h_prev, C_prev, W_f, W_i, W_C, W_o, b_f, b_i, b_C, b_o)
print("Forward h_t:", h_t) # Output: [0.11199714]
print("Forward C_t:", C_t) # Output: [0.2145628]
# Backward example: assume dh_next = [0.1], dC_next = [0.05]
dh_next = np.array([0.1])
dC_next = np.array([0.05])
dx_t, dh_prev, dC_prev, dW_f, db_f, dW_i, db_i, dW_C, db_C, dW_o, db_o = lstm_backward(dh_next, dC_next, cache, W_f, W_i, W_C, W_o)
print("Backward dx_t:", dx_t) # Output: [0.02164056]
print("Backward dh_prev:", dh_prev) # Output: [0.02164056]
print("Backward dC_prev:", dC_prev) # Output: [0.05780591]
print("Backward dW_f:", dW_f) # Output: [[0.00049199 0.00245997]]
print("Backward db_f:", db_f) # Output: [0.00491995]
print("Backward dW_i:", dW_i) # Output: [[0.00044162 0.00220808]]
print("Backward db_i:", db_i) # Output: [0.00441615]
print("Backward dW_C:", dW_C) # Output: [[0.00545376 0.02726878]]
print("Backward db_C:", db_C) # Output: [0.05453756]
print("Backward dW_o:", dW_o) # Output: [[0.00052643 0.00263213]]
print("Backward db_o:", db_o) # Output: [0.00526427]Notes
- This is a single-timestep LSTM with hidden size 1 for simplicity. In practice, LSTMs process sequences (multiple timesteps) and have larger hidden sizes; backpropagation through time (BPTT) unrolls the network over timesteps.
- The code uses NumPy; for real models, use PyTorch or TensorFlow for automatic differentiation and batching.
- Outputs are approximate due to floating-point precision but match the manual calculations.
- If you need a multi-timestep example, sequence processing, or integration into a full RNN, let me know!
E. Embedding
Forward Pass:
-
\( y = E[i] \),
where \( E \) is the embedding matrix,
\( i \) is the input index.
-
Index 1,
\( E = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \end{bmatrix}\),
\( y = [0.4,0.5,0.6] \).
Backward Pass:
-
Gradient \( \displaystyle \frac{\partial L}{\partial E[i]} += \frac{\partial L}{\partial y} \); other rows 0. (Sparse update).
-
\( \displaystyle \frac{\partial L}{\partial y} = [0.1, -0.1, 0.2] \),
so add to E[1].
Implementation:
import numpy as np
def embedding_forward(index, E):
return E[index]
def embedding_backward(dy, index, E_shape):
dE = np.zeros(E_shape)
dE[index] = dy
return dE
# Example
E = np.array([[0.1,0.2,0.3],[0.4,0.5,0.6]])
index = 1
y = embedding_forward(index, E)
dy = np.array([0.1, -0.1, 0.2])
dE = embedding_backward(dy, index, E.shape)
print("dE:\n", dE)
F. Attention (Scaled Dot-Product)
Forward Pass: \( \text{Attention} = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V \).
Backward Pass: Gradients for Q, K, V via chain rule on softmax and matmuls.
Numerical Example: Use previous. Backward is matrix derivs; code handles.
Implementation:
import numpy as np
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
def attention_forward(Q, K, V):
d = Q.shape[-1]
scores = np.dot(Q, K.T) / np.sqrt(d)
weights = softmax(scores)
attn = np.dot(weights, V)
return attn, (scores, weights, K, V) # Cache
def attention_backward(dattn, cache):
scores, weights, K, V = cache
dweights = np.dot(dattn, V.T)
dscores = weights * (dweights - np.sum(weights * dweights, axis=-1, keepdims=True))
dQ = np.dot(dscores, K) / np.sqrt(K.shape[-1])
dK = np.dot(dscores.T, Q) / np.sqrt(K.shape[-1])
dV = np.dot(weights.T, dattn)
return dQ, dK, dV
# Example
Q = K = V = np.array([[1.,0.],[0.,1.]])
attn, cache = attention_forward(Q, K, V)
dattn = np.array([[0.1,0.2],[ -0.1,0.3]])
dQ, dK, dV = attention_backward(dattn, cache)
print("dQ:\n", dQ)G. Normalization (Batch Normalization)
Forward Pass: Normalize, scale, shift.
Backward Pass: Gradients for input, gamma, beta via chain rule on mean/var.
Numerical Example: Previous forward. Backward computes dx, dgamma, dbeta.
Implementation:
import numpy as np
def batch_norm_forward(x, gamma, beta, epsilon=1e-4):
mu = np.mean(x)
var = np.var(x)
x_hat = (x - mu) / np.sqrt(var + epsilon)
y = gamma * x_hat + beta
return y, (x_hat, mu, var)
def batch_norm_backward(dy, cache, gamma):
x_hat, mu, var = cache
N = dy.shape[0]
dx_hat = dy * gamma
dvar = np.sum(dx_hat * (x - mu) * -0.5 * (var + epsilon)**(-1.5), axis=0)
dmu = np.sum(dx_hat * -1 / np.sqrt(var + epsilon), axis=0) + dvar * np.mean(-2 * (x - mu), axis=0)
dx = dx_hat / np.sqrt(var + epsilon) + dvar * 2 * (x - mu) / N + dmu / N
dgamma = np.sum(dy * x_hat, axis=0)
dbeta = np.sum(dy, axis=0)
return dx, dgamma, dbeta
# Example
x = np.array([1,2,3,4.])
gamma, beta = 1, 0
y, cache = batch_norm_forward(x, gamma, beta)
dy = np.array([0.1,0.2,-0.1,0.3])
dx, dgamma, dbeta = batch_norm_backward(dy, cache, gamma)
print("dx:", dx)
print("dgamma:", dgamma)
print("dbeta:", dbeta)H. Dropout

Dropout Neural Net Model. Left: A standard neural net with 2 hidden layers. Right: An example of a thinned net produced by applying dropout to the network on the left. Crossed units have been dropped. Source: Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Forward Pass: Mask during training.
Backward Pass: Same mask applied to upstream gradient (scale by 1/(1-p)).
Numerical Example: Same as forward; backward passes dy through mask.
Implementation:
import numpy as np
def dropout_forward(x, p, training=True):
if training:
mask = np.random.binomial(1, 1-p, size=x.shape) / (1-p)
y = x * mask
return y, mask
return x, None
def dropout_backward(dy, mask):
if mask is None:
return dy
return dy * mask
# Example
np.random.seed(0)
x = np.array([1,2,3,4.])
p = 0.5
y, mask = dropout_forward(x, p)
dy = np.array([0.1,0.2,0.3,0.4])
dx = dropout_backward(dy, mask)
print("dx:", dx)I. Flatten
Forward Pass: Reshape to 1D.
Backward Pass: Reshape upstream gradient back to original shape.
Numerical Example: - Forward: 2x2 to [1,2,3,4]. - Backward: dy = [0.1,0.2,0.3,0.4] -> reshape to 2x2.
Implementation:
import numpy as np
def flatten_forward(x):
return x.flatten(), x.shape
def flatten_backward(dy, orig_shape):
return dy.reshape(orig_shape)
# Example
x = np.array([[1,2],[3,4]])
y, shape = flatten_forward(x)
dy = np.array([0.1,0.2,0.3,0.4])
dx = flatten_backward(dy, shape)
print("dx:\n", dx)
J. Activation (ReLU)
Forward Pass:
- \( y = \max(0, x) \).
-
\( x = [-1, 0, 2, -3] \),
\( y = [0, 0, 2, 0] \).
Backward Pass:
-
\( \displaystyle \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot (x > 0) \).
-
\( dy = [0.5,-0.5,1,0] \),
\( dx = [0,0,1,0] \) (masked).
Implementation:
import numpy as np
def relu_forward(x):
return np.maximum(0, x), x
def relu_backward(dy, x_cache):
return dy * (x_cache > 0)
# Example
x = np.array([-1,0,2,-3])
y, x_cache = relu_forward(x)
dy = np.array([0.5,-0.5,1,0])
dx = relu_backward(dy, x_cache)
print("dx:", dx)
-
Mohd Halim Mohd Noor, Ayokunle Olalekan Ige: A Survey on State-of-the-art Deep Learning Applications and Challenges, 2025. ↩
-
Aston Zhang, Zachary C. Lipton, Mu Li, and Alexander J. Smola: Dive into Deep Learning, 2020. ↩
-
Ian Goodfellow, Yoshua Bengio, Aaron Courville: Deep Learning, 2016. ↩
-
Johannes Schneider, Michalis Vlachos: A Survey of Deep Learning: From Activations to Transformers, 2024. ↩
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. ↩
-
Adit Deshpande is a comprehensive resource for learning about deep learning, covering various topics such as neural networks, convolutional neural networks (CNNs), recurrent neural networks (RNNs), and more. It provides detailed explanations, code examples, and practical applications of deep learning concepts, making it suitable for both beginners and advanced learners. ↩
-
François Fleuret offers a collection of deep learning resources, including lectures, tutorials, and research papers, aimed at helping learners understand and apply deep learning techniques effectively. ↩