6. Multi-Layer Perceptron
Fast Forward: Multi-Layer Perceptrons (MLPs)
flowchart LR
classDef default fill:transparent,stroke:#333,stroke-width:1px;
classDef others fill:transparent,stroke:transparent,stroke-width:0px;
subgraph in[" "]
in1@{ shape: circle, label: " " }
in2@{ shape: circle, label: " " }
in3@{ shape: circle, label: " " }
inn@{ shape: circle, label: " " }
end
subgraph input
x1(["x<sub>1</sub>"])
x2(["x<sub>2</sub>"])
x3(["x<sub>3</sub>"])
xd(["..."]):::others
xn(["x<sub>n</sub>"])
xb(["1"])
end
subgraph hidden
direction TB
h1(["h<sub>1</sub>"])
h2(["h<sub>2</sub>"])
hd(["..."]):::others
hm(["h<sub>m</sub>"])
hb(["1"])
end
subgraph output
y1(["y<sub>1</sub>"])
yd(["..."]):::others
yk(["y<sub>k</sub>"])
end
in1@{ shape: circle, label: " " } --> x1
in2@{ shape: circle, label: " " } --> x2
in3@{ shape: circle, label: " " } --> x3
inn@{ shape: circle, label: " " } --> xn
x1 -->|"w<sub>11</sub>"|h1
x1 -->|"w<sub>12</sub>"|h2
x1 -->|"w<sub>1n</sub>"|hm
x2 -->|"w<sub>21</sub>"|h1
x2 -->|"w<sub>22</sub>"|h2
x2 -->|"w<sub>2n</sub>"|hm
x3 -->|"w<sub>31</sub>"|h1
x3 -->|"w<sub>32</sub>"|h2
x3 -->|"w<sub>3n</sub>"|hm
xn -->|"w<sub>i1</sub>"|h1
xn -->|"w<sub>i2</sub>"|h2
xn -->|"w<sub>in</sub>"|hm
xb -->|"b<sup>i</sup><sub>1</sub>"|h1
xb -->|"b<sup>i</sup><sub>2</sub>"|h2
xb -->|"b<sup>i</sup><sub>n</sub>"|hm
h1 -->|"v<sub>11</sub>"|y1
h1 -->|"v<sub>1k</sub>"|yk
h2 -->|"v<sub>21</sub>"|y1
h2 -->|"v<sub>2k</sub>"|yk
hm -->|"v<sub>m1</sub>"|y1
hm -->|"v<sub>mk</sub>"|yk
hb -->|"b<sup>h</sup><sub>1</sub>"|y1
hb -->|"b<sup>h</sup><sub>k</sub>"|yk
y1 --> out1@{ shape: dbl-circ, label: " " }
yk --> outn@{ shape: dbl-circ, label: " " }
style in fill:#fff,stroke:#666,stroke-width:0px
style input fill:#fff,stroke:#666,stroke-width:1px
style hidden fill:#fff,stroke:#666,stroke-width:1px
style output fill:#fff,stroke:#666,stroke-width:1pxwhere:
- \( y_k \) is the output for the \( k \)-th output neuron.
- \( x_i \) are the input features.
- \( w_{ij} \) are the weights connecting the \( i \)-th input to the \( j \)-th hidden neuron.
- \( v_{jk} \) are the weights connecting the \( j \)-th hidden neuron to the \( k \)-th output neuron.
- \( b^{h}_{i} \) is the bias for the \( i \)-th hidden neuron.
- \( b^{y}_{j} \) is the bias for the \( j \)-th output neuron.
- \( m \) is the number of hidden neurons.
- \( n \) is the number of input features.
- \( \sigma \) is the activation function applied to the weighted sums at each layer, such as sigmoid, tanh, or ReLU.
Matrix representation of the MLP architecture:
Multi-Layer Perceptron (MLP) Architecture.
| Sigmoid | Tanh | ReLU |
|---|---|---|
| \( \sigma(x) = \displaystyle \frac{1}{1 + e^{-x}} \) | \( \tanh(x) = \displaystyle \frac{e^{2x} - 1}{e^{2x} + 1} \) | \( \text{ReLU}(x) = \max(0, x) \) |
| \( \sigma'(x) = \sigma(x)(1 - \sigma(x)) \) | \( \tanh'(x) = 1 - \tanh^2(x) \) | \( \text{ReLU}'(x) = \begin{cases} 1 & \text{if } x > 0 \\ 0 & \text{if } x \leq 0 \end{cases} \) |
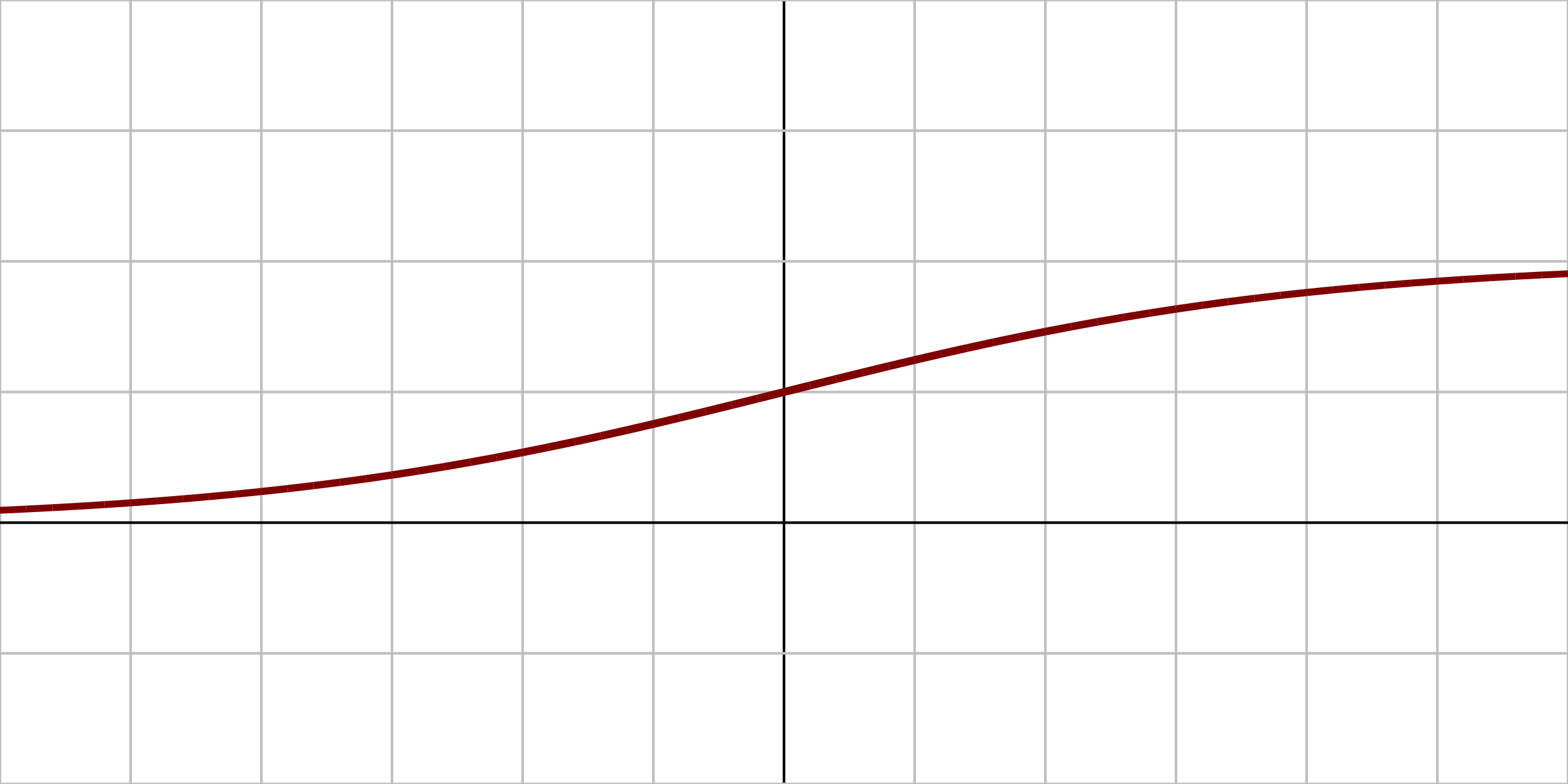 |  |  |
| Sigmoid is a smooth, S-shaped curve that outputs values between 0 and 1, making it suitable for binary classification tasks. | Tanh is a smooth curve that outputs values between -1 and 1, centering the data around zero, which can help with convergence in training. | ReLU is a piecewise linear function that outputs zero for negative inputs and the input itself for positive inputs, allowing for faster training and reducing the vanishing gradient problem. |
Backpropagation is the algorithm used to train multi-layer perceptrons (MLPs) by adjusting the weights and biases based on the error between the predicted output and the actual target. The process involves two main steps:
- Forward Pass: The input data is passed through the network, layer by layer, to compute the output. The output is compared to the target value to calculate the loss (error).
- Loss Calculation: Calculate the loss (error) between the predicted output and the actual target using a loss function, such as mean squared error or cross-entropy.
- Backward Pass: The error is propagated backward through the network to compute the gradients of the loss with respect to each weight and bias. These gradients are then used to update the weights and biases using an optimization algorithm, such as stochastic gradient descent (SGD) or Adam.
Feedforward
Consider a Multi-Layer Perceptron (MLP) with:
- 2 input neurons: \(x_1\) and \(x_2\)
- 1 hidden layer with 2 neurons: \(h_1\) and \(h_2\)
- 1 output neuron: \(y\)
We assume sigmoid activation functions for both the hidden and output layers:
, with derivative
The architecture can be visualized as follows:
flowchart LR
classDef default fill:transparent,stroke:#333,stroke-width:1px;
classDef others fill:transparent,stroke:transparent,stroke-width:0px;
subgraph input
x1(["x<sub>1</sub>"])
x2(["x<sub>2</sub>"])
xb(["1"])
end
subgraph hidden
h1(["h<sub>1</sub>"])
h2(["h<sub>2</sub>"])
hb(["1"])
end
subgraph output
y(["y"])
end
in1@{ shape: circle, label: " " } --> x1
in2@{ shape: circle, label: " " } --> x2
x1 -->|"w<sub>11</sub>"|h1
x1 -->|"w<sub>12</sub>"|h2
xb -->|"b<sup>h</sup><sub>1</sub>"|h1
x2 -->|"w<sub>21</sub>"|h1
x2 -->|"w<sub>22</sub>"|h2
xb -->|"b<sup>h</sup><sub>2</sub>"|h2
h1 -->|"v<sub>11</sub>"|y
h2 -->|"v<sub>21</sub>"|y
hb -->|"b<sup>y</sup><sub>1</sub>"|y
y(("ŷ")) --> out1@{ shape: dbl-circ, label: " " }
style input fill:#fff,stroke:#666,stroke-width:0px
style hidden fill:#fff,stroke:#666,stroke-width:0px
style output fill:#fff,stroke:#666,stroke-width:0pxIn mathematical terms, the feedforward process can be described as follows:
or, more canonical for our simple MLP:
- Hidden layer pre-activation:
- Hidden layer activations:
- Output layer pre-activation:
- Output layer activation:
where \( \sigma \) is the activation function, \( w_{ij} \) are the weights connecting inputs to hidden neurons, and \( v_{ij} \) are the weights connecting hidden neurons to output neurons. The biases \( b^h_1, b^h_2, \) and \( b^y_1 \) are added to the respective layers. \( \hat{y} \) is the predicted output of the MLP.
Loss Calculation
The loss function quantifies the difference between the predicted output and the actual target. For regression tasks, a common loss function is the Mean Squared Error (MSE):
where \( N \) is the number of samples, \( y_i \) is the true output, and \( \hat{y}_i \) is the predicted output.
Backpropagation: Computing Gradients
The backpropagation algorithm is a method used to train multi-layer perceptrons (MLPs) by minimizing the error between the predicted output and the actual target. It involves two main steps: the forward pass and the backward pass. The update of weights and biases is done using the gradients computed during the backward pass.
Backpropagation computes the partial derivatives of \(L\) with respect to each parameter using the chain rule, starting from the output and propagating errors backward.
Update Rule
To update parameters during training (e.g., via gradient descent with learning rate \(\eta\)), for each weight/bias \(p\):
This derivation assumes a single example; for batches, average the gradients. For other activations or losses (e.g., softmax + cross-entropy), the deltas would adjust accordingly, but the chain rule structure remains similar.
Step 1: Output Layer Error
The error term (delta) for the output is:
Step 2: Gradients for Output Weights and Bias
Remember
Using \(\sigma_y\):
\(\begin{align} \frac{\partial L}{\partial v_{11}} &= \sigma_y \cdot h_1 \\ \\ \overbrace{\frac{\partial L}{\partial u} \cdot \frac{\partial u}{\partial v_{11}}}^{\text{chain rule}} &= \sigma_y \cdot h_1 \end{align}\)
Similarly:
\(\begin{align} \frac{\partial L}{\partial v_{21}} &= \sigma_y \cdot h_2 \\ \\ \overbrace{\frac{\partial L}{\partial u} \cdot \frac{\partial u}{\partial v_{21}}}^{\text{chain rule}} &= \sigma_y \cdot h_2 \end{align}\)
For the bias:
\(\begin{align} \frac{\partial L}{\partial b^y_1} &= \sigma_y \cdot 1 \\ \\ \overbrace{\frac{\partial L}{\partial u} \cdot \frac{\partial u}{\partial b^y_1}}^{\text{chain rule}} &= \sigma_y \end{align}\)
Step 3: Hidden Layer Errors
Remember
Propagate the error back to the hidden layer. For each hidden neuron:
\(\begin{array} \displaystyle \sigma_{h_1} &= \displaystyle \frac{\partial L}{\partial z_1} \\ &= \displaystyle \frac{\partial L}{\partial h_1} & \displaystyle \cdot \frac{\partial h_1}{\partial z_1} \\ &= \displaystyle \overbrace{ \left( \frac{\partial L}{\partial u} \cdot \frac{\partial u}{\partial h_1} \right)}^{\text{chain rule}} & \cdot \sigma'(z_1) \\ &= (\sigma_y \cdot v_1) & \cdot \sigma'(z_1) \\ &= (\sigma_y \cdot v_1) & \cdot h_1(1 - h_1) \end{array}\)
Similarly:
\(\sigma_{h_2} = (\sigma_y \cdot v_2) \cdot h_2(1 - h_2)\)
Step 4: Gradients for Hidden Weights and Biases
Using the hidden deltas:
\(\begin{align} \frac{\partial L}{\partial w_{11}} &= \frac{\partial L}{\partial z_1} \cdot \frac{\partial z_1}{\partial w_{11}} &= \sigma_{h_1} \cdot x_1 \end{align}\)
\(\begin{align} \frac{\partial L}{\partial w_{21}} &= \frac{\partial L}{\partial z_1} \cdot \frac{\partial z_1}{\partial w_{21}} &= \sigma_{h_1} \cdot x_2 \end{align}\)
\(\begin{align} \frac{\partial L}{\partial w_{12}} &= \frac{\partial L}{\partial z_2} \cdot \frac{\partial z_2}{\partial w_{12}} &= \sigma_{h_2} \cdot x_1 \end{align}\)
\(\begin{align} \frac{\partial L}{\partial w_{22}} &= \frac{\partial L}{\partial z_2} \cdot \frac{\partial z_2}{\partial w_{22}} &= \sigma_{h_2} \cdot x_2 \end{align}\)
similarly for biases:
\(\begin{align} \frac{\partial L}{\partial b_1} &= \sigma_{h_1} \cdot 1 &= \sigma_{h_1} \end{align}\)
\(\begin{align} \frac{\partial L}{\partial b_2} &= \sigma_{h_2} \cdot 1 &= \sigma_{h_2} \end{align}\)
Step 5: Update Weights and Biases
Remember
Finally, update the weights and biases using the computed gradients and a learning rate \(\eta\):
\(\begin{align} v_{11} & \leftarrow v_{11} - \eta \cdot \frac{\partial L}{\partial v_{11}} \\ v_{21} & \leftarrow v_{21} - \eta \cdot \frac{\partial L}{\partial v_{21}} \\ \\ w_{11} & \leftarrow w_{11} - \eta \cdot \frac{\partial L}{\partial w_{11}} \\ w_{21} & \leftarrow w_{21} - \eta \cdot \frac{\partial L}{\partial w_{21}} \\ w_{12} & \leftarrow w_{12} - \eta \cdot \frac{\partial L}{\partial w_{12}} \\ w_{22} & \leftarrow w_{22} - \eta \cdot \frac{\partial L}{\partial w_{22}} \\ \\ b^h_1 & \leftarrow b^h_1 - \eta \cdot \frac{\partial L}{\partial b^h_1} \\ b^h_2 & \leftarrow b^h_2 - \eta \cdot \frac{\partial L}{\partial b^h_2} \\ \\ b^y_1 & \leftarrow b^y_1 - \eta \cdot \frac{\partial L}{\partial b^y_1} \end{align}\)
Numerical Simulation
Based on the MLP architecture and backpropagation steps described above, we can implement a simple numerical simulation demonstrate the training process of a multi-layer perceptron (MLP) using backpropagation.
Initizalization
The weight matrices and bias vectors are initialized as follows (randomically in \([0,1]\)):
Forward Pass
For the sample:
-
Compute hidden layer pre-activation:
\[ \begin{array}{ll} \mathbf{z} &= \mathbf{W} \mathbf{x} + \mathbf{b}^h \\ &= \begin{bmatrix} 0.2 & 0.4 \\ 0.6 & 0.8 \end{bmatrix} \begin{bmatrix} 0.5 \\ 0.8 \end{bmatrix} + \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} \\ &= \begin{bmatrix} 0.2*0.5 + 0.4*0.8 + 0.1 \\ 0.6*0.5 + 0.8*0.8 + 0.2 \end{bmatrix} \\ \mathbf{z} &= \begin{bmatrix} 0.52 \\ 1.14 \end{bmatrix} \end{array} \] -
Compute hidden layer activations:
\[ \begin{array}{ll} \mathbf{h} &= \sigma(\mathbf{z}) \\ &= \sigma \left( \begin{bmatrix} 0.52 \\ 1.14 \end{bmatrix} \right) \\ &= \begin{bmatrix} \displaystyle \frac{1}{1 + e^{-0.52}} \\ \displaystyle \frac{1}{1 + e^{-1.14}} \end{bmatrix} \\ \mathbf{h} &\approx \begin{bmatrix} 0.627 \\ 0.758 \end{bmatrix} \end{array} \] -
Compute output layer pre-activation:
\[ \begin{array}{ll} u &= \mathbf{V} \mathbf{h} + b^y \\ &= \begin{bmatrix} 0.3 & 0.5 \end{bmatrix} \begin{bmatrix} 0.627 \\ 0.758 \end{bmatrix} + 0.4 \\ &= 0.3*0.627 + 0.5*0.758 + 0.4 \\ u &\approx 0.967 \end{array} \] -
Compute output layer activation:
\[ \begin{array}{ll} \hat{y} &= \sigma(u) \\ &= \sigma(0.967) \\ &= \displaystyle \frac{1}{1 + e^{-0.967}} \\ \hat{y} &\approx 0.725 \end{array} \]
Loss Calculation
Using Mean Squared Error (MSE):
Backward Pass
-
Compute output layer gradients:
\[ \begin{array}{ll} \displaystyle \frac{\partial L}{\partial \hat{y}} &= \displaystyle \frac{\partial L}{\partial u} \cdot \frac{\partial u}{\partial \hat{y}} \\ &= 2(y - \hat{y}) \cdot \hat{y} (1 - \hat{y}) \\ &\approx 2(0 - 0.725) \cdot 0.725 \cdot (1 - 0.725) \\ &\approx -0.289 \end{array} \] -
Compute hidden layer gradients:
\[ \begin{array}{ll} \displaystyle \frac{\partial L}{\partial \mathbf{h}} &= \displaystyle \frac{\partial L}{\partial u} \cdot \frac{\partial u}{\partial \mathbf{h}} \\ &= \displaystyle \frac{\partial L}{\partial \hat{y}} \cdot \mathbf{V} \cdot \mathbf{h} (1 - \mathbf{h}) \\ &\approx -0.289 \cdot \begin{bmatrix} 0.3 & 0.5 \end{bmatrix} \cdot \begin{bmatrix} 0.627 \\ 0.758 \end{bmatrix} \cdot \left(1 - \begin{bmatrix} 0.627 \\ 0.758 \end{bmatrix} \right) \\ &\approx -0.289 \cdot \underbrace{ \begin{bmatrix} 0.3 & 0.5 \end{bmatrix} \cdot \begin{bmatrix} 0.627 \\ 0.758 \end{bmatrix} \cdot \begin{bmatrix} 0.373 \\ 0.242 \end{bmatrix} }_{\text{element-wise multiplication}} \\ &\approx -0.289 \cdot \begin{bmatrix} 0.07 \\ 0.092 \end{bmatrix} \\ &\approx \begin{bmatrix} -0.020 \\ -0.026 \end{bmatrix} \end{array} \] -
Compute weight gradients:
\[ \begin{array}{ll} \displaystyle \frac{\partial L}{\partial \mathbf{W}} &= \displaystyle \frac{\partial L}{\partial \mathbf{h}} \cdot \frac{\partial \mathbf{h}}{\partial \mathbf{W}} \\ &= \begin{bmatrix} -0.020 \\ -0.026 \end{bmatrix} \cdot \mathbf{x} \\ &\approx \underbrace{ \begin{bmatrix} -0.020 \\ -0.026 \end{bmatrix} \cdot \begin{bmatrix} 0.5 & 0.5 \\ 0.8 & 0.8 \end{bmatrix} }_{\text{element-wise multiplication}} \\ &\approx \begin{bmatrix} -0.010 & -0.013 \\ -0.016 & -0.021 \end{bmatrix} \end{array} \] -
Compute bias gradients:
\[ \begin{array}{ll} \displaystyle \frac{\partial L}{\partial \mathbf{b^y}} &= \displaystyle \frac{\partial L}{\partial \mathbf{y}} \cdot \frac{\partial \mathbf{y}}{\partial \mathbf{b^y}} \\ &\approx -0.289 \cdot 1 \\ &\approx -0.289 \end{array} \]\[ \begin{array}{ll} \displaystyle \frac{\partial L}{\partial \mathbf{b^h}} &= \displaystyle \frac{\partial L}{\partial \mathbf{h}} \cdot \frac{\partial \mathbf{h}}{\partial \mathbf{b^h}} \\ &\approx \begin{bmatrix} -0.020 \\ -0.026 \end{bmatrix} \cdot 1 \\ &\approx \begin{bmatrix} -0.020 \\ -0.026 \end{bmatrix} \end{array} \] -
Update the parameters:
\[ \begin{array}{ll} \mathbf{W} &\leftarrow \mathbf{W} - \eta \displaystyle \frac{\partial L}{\partial \mathbf{W}} \\ &\leftarrow \displaystyle \begin{bmatrix} 0.2 & 0.4 \\ 0.6 & 0.8 \end{bmatrix} - 0.7 \cdot \displaystyle \begin{bmatrix} -0.010 & -0.013 \\ -0.016 & -0.021 \end{bmatrix} \\ &\leftarrow \begin{bmatrix} 0.207 & 0.409 \\ 0.611 & 0.815 \end{bmatrix} \\ \mathbf{V} &\leftarrow \mathbf{V} - \eta \displaystyle \frac{\partial L}{\partial \mathbf{V}} \\ &\leftarrow \displaystyle \begin{bmatrix} 0.3 & 0.5 \end{bmatrix} - 0.7 \cdot \displaystyle \begin{bmatrix} -0.020 \\ -0.026 \end{bmatrix} \\ &\leftarrow \begin{bmatrix} 0.314 & 0.518 \end{bmatrix}\\ \\ \mathbf{b^y} &\leftarrow \mathbf{b^y} - \eta \displaystyle \frac{\partial L}{\partial \mathbf{b^y}} \\ &\leftarrow 0.4 - 0.7 \cdot (-0.289) \\ &\leftarrow 0.602 \\ \mathbf{b^h} &\leftarrow \mathbf{b^h} - \eta \displaystyle \frac{\partial L}{\partial \mathbf{b^h}} \\ &\leftarrow \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix} - 0.7 \cdot \begin{bmatrix} -0.020 \\ -0.026 \end{bmatrix} \\ &\leftarrow \begin{bmatrix} 0.114 \\ 0.218 \end{bmatrix} \end{array} \] -
Repeat the training process for each sample or multiple epochs. About the training process, there are two main approaches: online learning and batch learning:
-
Online learning is a method of training multi-layer perceptrons (MLPs) where the model is updated after each training example. This approach allows for faster convergence and can be more effective in scenarios with large datasets or when the data is not stationary.
-
Batch learning, on the other hand, involves updating the model after processing a batch of training examples. This method can lead to more stable updates and is often used in practice due to its efficiency in utilizing computational resources.
-
Additional
For a more intuitive understanding of neural networks, I highly recommend the following video series by 3Blue1Brown, which provides excellent visual explanations of the concepts: https://www.3blue1brown.com/lessons/neural-networks
-
Haykin, S. (1994). Neural Networks: A Comprehensive Foundation. Prentice Hall. ↩
-
Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. ↩
-
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. ↩
-
Physics of Neural Networks, Book Series. ↩
-
Introduction to Mathematical Optimization, by Indrajit Ghosh. ↩