6. Multi-Layer Perceptron
Apresentação: Perceptrons Multi-Camada (MLPs)
flowchart LR
classDef default fill:transparent,stroke:#333,stroke-width:1px;
classDef others fill:transparent,stroke:transparent,stroke-width:0px;
subgraph in[" "]
in1@{ shape: circle, label: " " }
in2@{ shape: circle, label: " " }
in3@{ shape: circle, label: " " }
inn@{ shape: circle, label: " " }
end
subgraph entrada
x1(["x<sub>1</sub>"])
x2(["x<sub>2</sub>"])
x3(["x<sub>3</sub>"])
xd(["..."]):::others
xn(["x<sub>n</sub>"])
xb(["1"])
end
subgraph oculta
direction TB
h1(["h<sub>1</sub>"])
h2(["h<sub>2</sub>"])
hd(["..."]):::others
hm(["h<sub>m</sub>"])
hb(["1"])
end
subgraph saida
y1(["y<sub>1</sub>"])
yd(["..."]):::others
yk(["y<sub>k</sub>"])
end
in1@{ shape: circle, label: " " } --> x1
in2@{ shape: circle, label: " " } --> x2
in3@{ shape: circle, label: " " } --> x3
inn@{ shape: circle, label: " " } --> xn
x1 -->|"w<sub>11</sub>"|h1
x1 -->|"w<sub>12</sub>"|h2
x1 -->|"w<sub>1n</sub>"|hm
x2 -->|"w<sub>21</sub>"|h1
x2 -->|"w<sub>22</sub>"|h2
x2 -->|"w<sub>2n</sub>"|hm
x3 -->|"w<sub>31</sub>"|h1
x3 -->|"w<sub>32</sub>"|h2
x3 -->|"w<sub>3n</sub>"|hm
xn -->|"w<sub>i1</sub>"|h1
xn -->|"w<sub>i2</sub>"|h2
xn -->|"w<sub>in</sub>"|hm
xb -->|"b<sup>i</sup><sub>1</sub>"|h1
xb -->|"b<sup>i</sup><sub>2</sub>"|h2
xb -->|"b<sup>i</sup><sub>n</sub>"|hm
h1 -->|"v<sub>11</sub>"|y1
h1 -->|"v<sub>1k</sub>"|yk
h2 -->|"v<sub>21</sub>"|y1
h2 -->|"v<sub>2k</sub>"|yk
hm -->|"v<sub>m1</sub>"|y1
hm -->|"v<sub>mk</sub>"|yk
hb -->|"b<sup>h</sup><sub>1</sub>"|y1
hb -->|"b<sup>h</sup><sub>k</sub>"|yk
y1 --> out1@{ shape: dbl-circ, label: " " }
yk --> outn@{ shape: dbl-circ, label: " " }
style in fill:#fff,stroke:#666,stroke-width:0px
style entrada fill:#fff,stroke:#666,stroke-width:1px
style oculta fill:#fff,stroke:#666,stroke-width:1px
style saida fill:#fff,stroke:#666,stroke-width:1pxonde:
- \(y_k\) é a saída para o \(k\)-ésimo neurônio de saída.
- \(x_i\) são as features de entrada.
- \(w_{ij}\) são os pesos conectando a \(i\)-ésima entrada ao \(j\)-ésimo neurônio oculto.
- \(v_{jk}\) são os pesos conectando o \(j\)-ésimo neurônio oculto ao \(k\)-ésimo neurônio de saída.
- \(b^{h}_{i}\) é o bias para o \(i\)-ésimo neurônio oculto.
- \(b^{y}_{j}\) é o bias para o \(j\)-ésimo neurônio de saída.
- \(m\) é o número de neurônios ocultos.
- \(n\) é o número de features de entrada.
- \(\sigma\) é a função de ativação aplicada às somas ponderadas em cada camada, como sigmoid, tanh ou ReLU.
Representação matricial da arquitetura MLP:
| Sigmoid | Tanh | ReLU |
|---|---|---|
| \(\sigma(x) = \displaystyle \frac{1}{1 + e^{-x}}\) | \(\tanh(x) = \displaystyle \frac{e^{2x} - 1}{e^{2x} + 1}\) | \(\text{ReLU}(x) = \max(0, x)\) |
| \(\sigma'(x) = \sigma(x)(1 - \sigma(x))\) | \(\tanh'(x) = 1 - \tanh^2(x)\) | \(\text{ReLU}'(x) = \begin{cases} 1 & \text{se } x > 0 \\ 0 & \text{se } x \leq 0 \end{cases}\) |
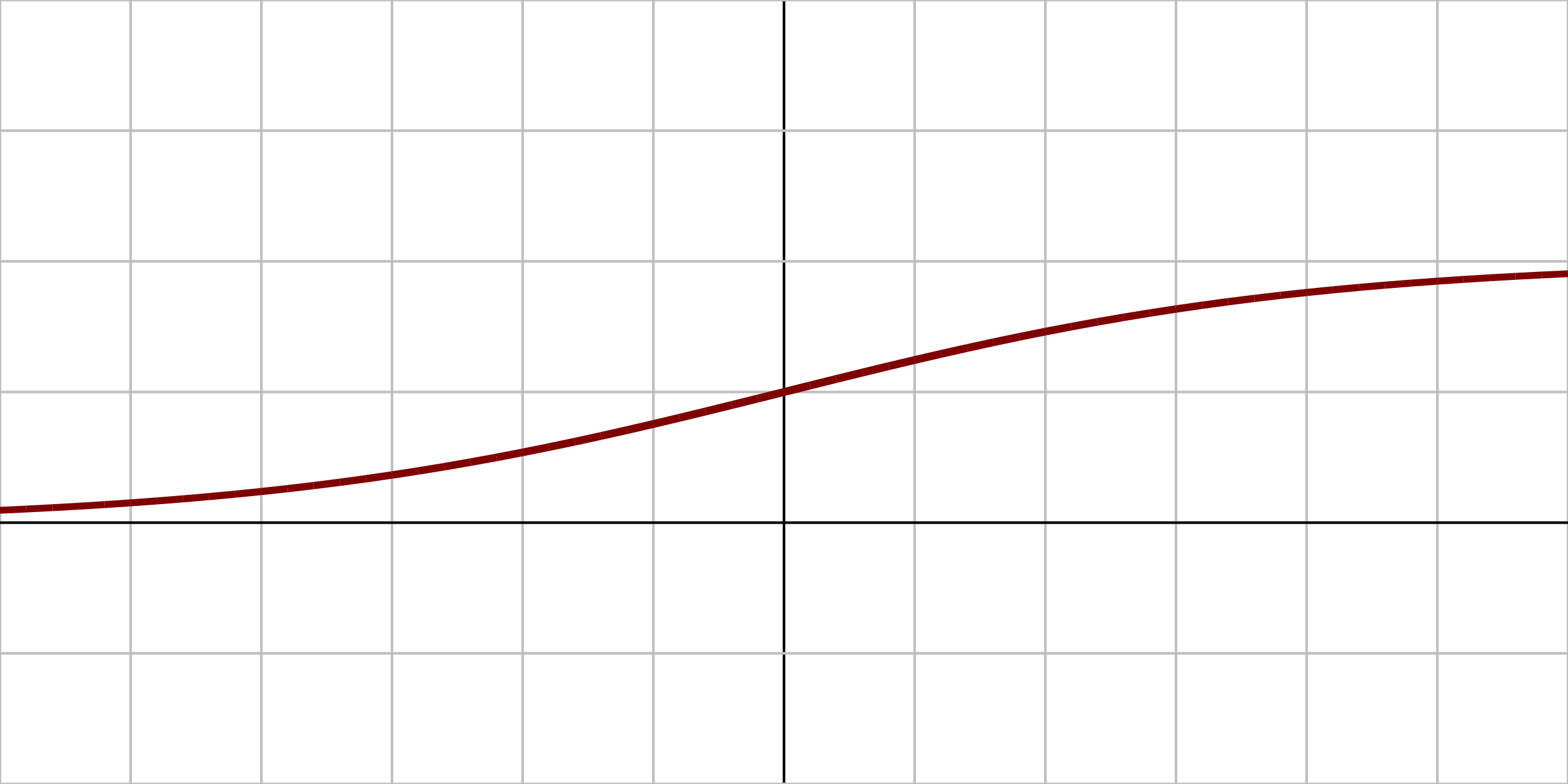 |  |  |
| Sigmoid é uma curva S suave que produz valores entre 0 e 1, sendo adequada para classificação binária. | Tanh é uma curva suave que produz valores entre -1 e 1, centralizando os dados em zero, o que pode ajudar na convergência. | ReLU é uma função linear por partes que produz zero para entradas negativas e a própria entrada para positivas, permitindo treinamento mais rápido e reduzindo o gradiente desvanecente. |
A retropropagação é o algoritmo usado para treinar MLPs ajustando pesos e biases com base no erro entre a saída prevista e o alvo real. O processo envolve dois passos principais:
- Passagem Direta: Os dados de entrada passam pela rede, camada por camada, para calcular a saída. A saída é comparada ao valor alvo para calcular a perda.
- Cálculo da Perda: Calcula-se a perda entre a saída prevista e o alvo real usando uma função de perda, como erro quadrático médio ou cross-entropy.
- Passagem Reversa: O erro é propagado de volta pela rede para calcular os gradientes da perda em relação a cada peso e bias. Esses gradientes são usados para atualizar os pesos e biases usando um algoritmo de otimização, como SGD ou Adam.
Passagem Direta (Feedforward)
Considere um MLP com:
- 2 neurônios de entrada: \(x_1\) e \(x_2\)
- 1 camada oculta com 2 neurônios: \(h_1\) e \(h_2\)
- 1 neurônio de saída: \(y\)
Assumimos funções de ativação sigmoid para as camadas oculta e de saída:
com derivada \(\sigma'(z) = \sigma(z)(1 - \sigma(z))\).
Em termos matemáticos, o processo de passagem direta é descrito como:
ou, mais canonicamente:
- Pré-ativação da camada oculta:
- Ativações da camada oculta:
- Pré-ativação da camada de saída:
- Ativação da camada de saída:
Cálculo da Perda
A função de perda quantifica a diferença entre a saída prevista e o alvo real. Para tarefas de regressão, o Erro Quadrático Médio (MSE) é comum:
Retropropagação: Calculando Gradientes
O algoritmo de retropropagação calcula as derivadas parciais de \(L\) em relação a cada parâmetro usando a regra da cadeia, partindo da saída e propagando os erros de volta.
Regra de Atualização
Para atualizar parâmetros (ex: via gradiente descendente com taxa de aprendizado \(\eta\)):
Passo 1: Erro da Camada de Saída
Passo 2: Gradientes para Pesos e Bias de Saída
Passo 3: Erros da Camada Oculta
Passo 4: Gradientes para Pesos e Biases Ocultos
Passo 5: Atualizar Pesos e Biases
Usando os gradientes calculados e a taxa de aprendizado \(\eta\):
Simulação Numérica
Com base na arquitetura MLP e nos passos de retropropagação descritos, podemos implementar uma simulação numérica simples para demonstrar o processo de treinamento.
Inicialização
As matrizes de pesos e vetores de bias são inicializados aleatoriamente em \([0,1]\):
Passagem Direta
Para a amostra \(\mathbf{x} = [0.5, 0.8]^T\), \(y = 0\):
- Pré-ativação oculta: \(\mathbf{z} = [0.52, 1.14]^T\)
- Ativações ocultas: \(\mathbf{h} \approx [0.627, 0.758]^T\)
- Pré-ativação de saída: \(u \approx 0.967\)
- Ativação de saída: \(\hat{y} \approx 0.725\)
Cálculo da Perda
Passagem Reversa
- \(\partial L / \partial u \approx -0.289\)
- Gradientes da camada oculta: \(\approx [-0.020, -0.026]^T\)
- Pesos atualizados: \(\mathbf{W} \leftarrow \begin{bmatrix} 0.207 & 0.409 \\ 0.611 & 0.815 \end{bmatrix}\)
Repita o processo de treinamento para cada amostra ou múltiplas épocas.
- Aprendizado online: atualiza o modelo após cada exemplo de treinamento.
- Aprendizado em batch: atualiza o modelo após processar um batch de exemplos.
Recursos Adicionais
Para uma compreensão mais intuitiva de redes neurais, recomendo a série de vídeos do 3Blue1Brown: https://www.3blue1brown.com/lessons/neural-networks
Interativo: Visualizador de Passagem Direta do MLP
Observe as ativações se propagando por uma rede 2-entradas → 3-ocultos → 2-saídas. Ajuste os sliders de entrada e veja os valores fluírem camada por camada.