5. Perceptron
Inspiração Biológica
Desde o início das redes neurais artificiais (ANNs), seu design foi fortemente influenciado pela estrutura e função das redes neurais biológicas. O cérebro humano, com sua complexa rede de neurônios, serve como modelo fundamental para entender como as ANNs podem processar informações. A base de uma ANN é um neurônio, que imita o comportamento dos neurônios biológicos. Cada neurônio recebe entradas, as processa e produz uma saída, similar à forma como os neurônios biológicos se comunicam através de sinapses.

Diagrama de um Neurônio.
Fonte: Wikipedia - Neurônio
O neurônio biológico consiste em um corpo celular (soma), dendritos e um axônio. Os dendritos recebem sinais de outros neurônios, o soma processa esses sinais e o axônio transmite a saída para outros neurônios. Essa estrutura permite interações complexas e processamento de informações, essencial para aprendizado e tomada de decisão em sistemas biológicos. O sinal produzido por um neurônio é conhecido como potencial de ação, um impulso elétrico que percorre o axônio para se comunicar com outros neurônios. O potencial de ação é gerado quando o neurônio recebe entrada suficiente de seus dendritos, levando a uma mudança no potencial elétrico através de sua membrana. Esse processo é conhecido como ativação neural e é crucial para o funcionamento tanto de neurônios biológicos quanto artificiais.

Potencial de ação.
Fonte: Wikipedia - Potencial de ação
Com base nessa inspiração biológica, McCulloch e Pitts1 propuseram o primeiro modelo matemático de um neurônio em 1943. Esse modelo lançou as bases para o desenvolvimento de neurônios artificiais, os blocos construtivos das ANNs. O neurônio McCulloch-Pitts é um modelo binário simples que produz um sinal baseado em se a soma ponderada de suas entradas excede um certo limiar.
Esta equação descreve como a saída do neurônio \(N_i\) no tempo \(t+1\) é determinada pela soma ponderada de suas entradas \(N_j\) no tempo \(t\), ajustada por um limiar \(\theta_i(t)\). A função \(H\) é uma função degrau que ativa o neurônio se a entrada exceder o limiar. Os resultados do modelo McCulloch-Pitts são binários — a saída é 0 ou 1, correspondendo ao neurônio inativo ou ativo, respectivamente.
Fundamentos Matemáticos
Os fundamentos matemáticos das redes neurais artificiais são construídos sobre álgebra linear, cálculo e teoria da probabilidade.
O Perceptron, introduzido por Rosenblatt2 em 1958, é uma das formas mais antigas e simples de ANN. Consiste em uma única camada de neurônios que pode classificar dados linearmente separáveis. O algoritmo do Perceptron ajusta os pesos das entradas com base no erro na saída, permitindo que aprenda a partir de exemplos.
O Perceptron pode ser matematicamente descrito como:
flowchart LR
classDef default fill:#fff,stroke:#333,stroke-width:1px;
subgraph input["entradas"]
direction TB
x1(["x<sub>1</sub>"])
x2(["x<sub>2</sub>"])
end
subgraph hidden[" "]
direction LR
S(["Σ"])
subgraph af["função de ativação"]
f(["ƒ(Σ)"])
end
end
subgraph bias["bias"]
direction TB
b1(["b"])
end
in1@{ shape: circle, label: " " } --> x1
in2@{ shape: circle, label: " " } --> x2
x1 -->|"w<sub>1</sub>"| S
x2 -->|"w<sub>2</sub>"| S
b1 --> S
S --> f
subgraph outputs["saída"]
direction TB
out1
end
f --> out1@{ shape: dbl-circ, label: "y" }
style input fill:#fff,stroke:#fff,stroke-width:0px
style bias fill:#fff,stroke:#fff,stroke-width:0px
style hidden fill:#fff,stroke:#fff,stroke-width:0px
style outputs fill:#fff,stroke:#fff,stroke-width:0pxO Perceptron calcula a saída \(y\) como:
Um perceptron é um neurônio artificial simples que recebe múltiplas entradas, aplica pesos a elas, as soma, adiciona um bias e passa o resultado por uma função de ativação (tipicamente uma função degrau) para produzir uma saída binária. É usado para resolver problemas de classificação linearmente separáveis.
- Entrada: vetor de features \(\mathbf{x} = [x_1, x_2, \dots, x_n]\).
- Pesos: vetor \(\mathbf{w} = [w_1, w_2, \dots, w_n]\) representando a importância de cada entrada.
- Bias: escalar \(b\) que desloca a fronteira de decisão.
- Saída: \(y = \text{ativação}(\mathbf{w} \cdot \mathbf{x} + b)\), onde a ativação é a função degrau.
O objetivo do treinamento é encontrar os pesos ótimos \(\mathbf{w}\) e bias \(b\) para que o perceptron classifique corretamente os dados de treinamento.
Processo de Treinamento do Perceptron
O algoritmo de treinamento ajusta os pesos e bias iterativamente com base em erros de classificação.
1. Inicializar Pesos e Bias
Comece com valores aleatórios pequenos para os pesos \(\mathbf{w}\) e bias \(b\), ou inicialize-os com zero.
2. Fornecer Dados de Treinamento
O conjunto de treinamento consiste em pares entrada-saída \(\{(\mathbf{x}^{(i)}, y^{(i)})\}\). Os dados devem ser linearmente separáveis para que o perceptron convirja.
3. Passagem Direta: Calcular Predição
Para cada exemplo \(\mathbf{x}^{(i)}\): calcule a soma ponderada \(z = \mathbf{w} \cdot \mathbf{x}^{(i)} + b\) e aplique a função de ativação para obter \(\hat{y}^{(i)}\).
4. Calcular Erro
\(\text{erro} = y^{(i)} - \hat{y}^{(i)}\)
5. Atualizar Pesos e Bias
Se a predição estiver incorreta, ajuste usando a regra de aprendizado do perceptron4:
onde \(\eta\) é a taxa de aprendizado.
6. Iterar
Repita os passos 3–5 para todos os exemplos de treinamento (uma passagem pelo conjunto é chamada de época).
Critério de Parada
Continue iterando por um número fixo de épocas ou até que o perceptron classifique corretamente todos os exemplos de treinamento.
7. Convergência
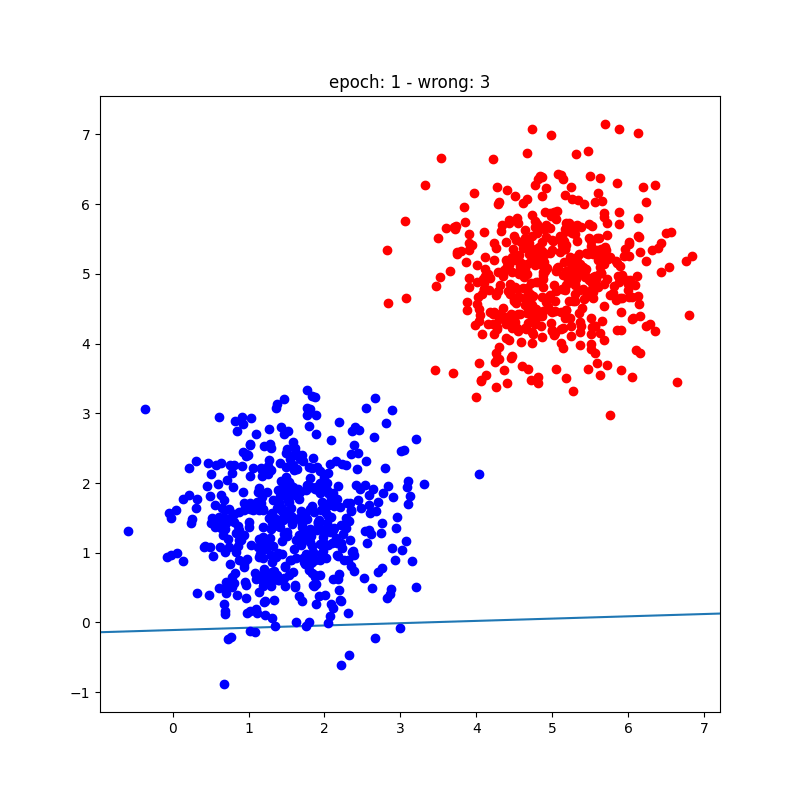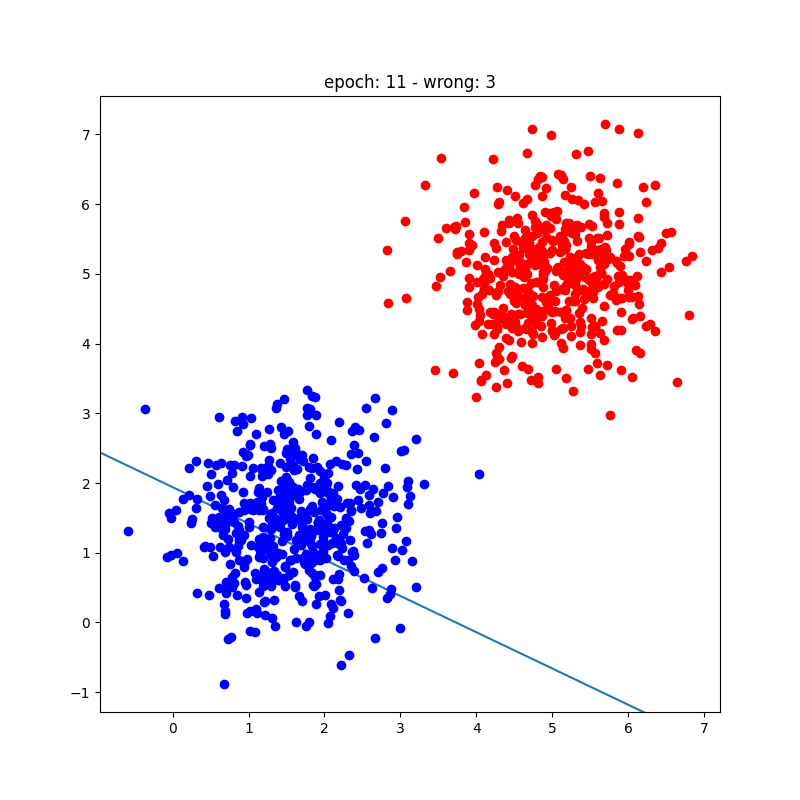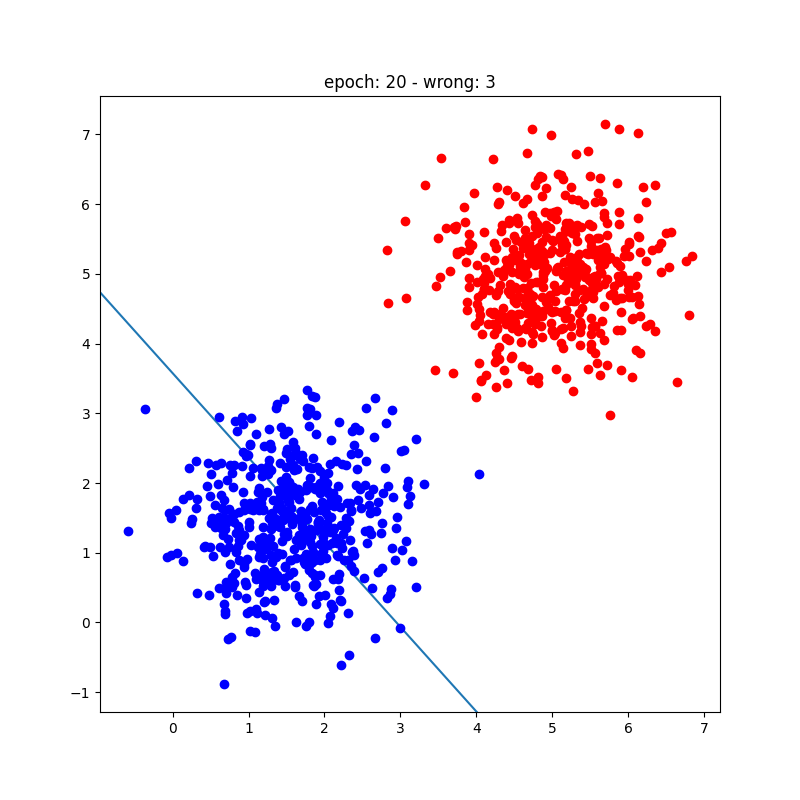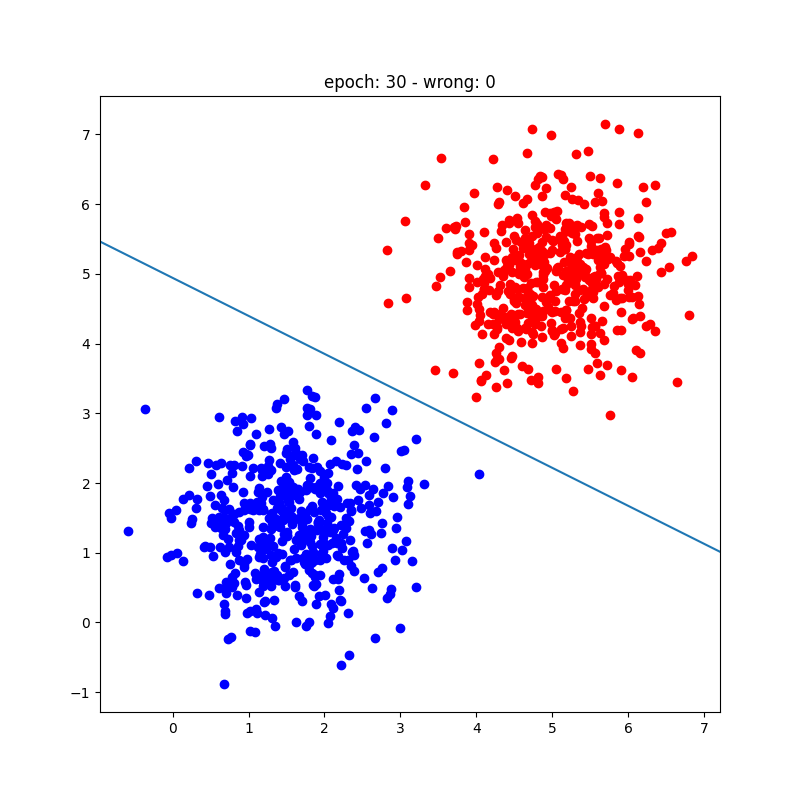
Se os dados são linearmente separáveis, o perceptron é garantido de convergir para uma solução que classifica corretamente todos os exemplos.
Critério de Parada
Se os dados não são linearmente separáveis, o algoritmo não converge e pode oscilar. Nesses casos, limite o número de épocas ou use um modelo diferente.
Intuição por Trás do Treinamento
- O perceptron aprende ajustando a fronteira de decisão (um hiperplano definido por \(\mathbf{w} \cdot \mathbf{x} + b = 0\)) para separar as duas classes.
- Cada atualização de peso move o hiperplano ligeiramente para reduzir erros de classificação.
- A taxa de aprendizado \(\eta\) controla o quão agressivamente o hiperplano é ajustado.
Exemplo: Treinando um Perceptron
Suponha um dataset com duas features \(\mathbf{x} = [x_1, x_2]\) e rótulos binários (0 ou 1).
Dataset:
| \(x_1\) | \(x_2\) | Rótulo (\(y\)) |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 1 |
| -1 | -1 | 0 |
| -2 | -1 | 0 |
Passo a Passo:
-
Inicializar: \(\mathbf{w} = [0, 0]\), \(b = 0\), \(\eta = 0.1\).
-
Primeiro Exemplo: \(\mathbf{x}^{(1)} = [1, 1]\), \(y^{(1)} = 1\). Calcula \(z = 0\), então \(\hat{y}^{(1)} = 1\). Erro = 0. Nenhuma atualização.
-
Segundo Exemplo: \(\mathbf{x}^{(2)} = [2, 2]\), \(y^{(2)} = 1\). Calcula \(z = 0\), então \(\hat{y}^{(2)} = 1\). Erro = 0.
-
Terceiro Exemplo: \(\mathbf{x}^{(3)} = [-1, -1]\), \(y^{(3)} = 0\). \(z = 0\), \(\hat{y}^{(3)} = 1\). Erro = −1. Atualiza: \(\mathbf{w} = [0.1, 0.1]\), \(b = -0.1\).
-
Quarto Exemplo: \(\mathbf{x}^{(4)} = [-2, -1]\). \(z = -0.4\), \(\hat{y}^{(4)} = 0\). Erro = 0.
-
Repetir: Continue iterando até todos os exemplos serem classificados corretamente.
Pontos Principais
- Separabilidade Linear: O perceptron só funciona para datasets onde uma única hiperplano pode separar as classes. Para dados não linearmente separáveis (ex: problema XOR), um único perceptron falha.
- Taxa de Aprendizado: Escolher um \(\eta\) adequado é crucial. Muito grande e o algoritmo pode oscilar; muito pequeno e pode convergir lentamente.
- Convergência: O teorema de convergência do perceptron garante que o algoritmo encontrará uma solução em um número finito de passos se os dados são linearmente separáveis.
Visualizando a Fronteira de Decisão
A fronteira de decisão é o hiperplano onde \(\mathbf{w} \cdot \mathbf{x} + b = 0\). Para um dataset 2D (\(x_1, x_2\)), isso é uma linha:
Durante o treinamento, os pesos e bias são ajustados para mover essa linha de forma que separe as duas classes corretamente.
Considerações Práticas
- Pré-processamento: Normalize ou padronize as features de entrada para garantir que estejam em escalas similares.
- Épocas: Defina um número máximo de épocas para evitar loops infinitos se os dados não são linearmente separáveis.
- Extensões: Para lidar com problemas multiclasse, use múltiplos perceptrons (um-vs-resto) ou avance para modelos como MLPs ou máquinas de vetores de suporte (SVMs).
Limitações do Perceptron
-
Dados Linearmente Separáveis: O perceptron só resolve problemas onde as classes são linearmente separáveis. O problema XOR5 é o exemplo clássico dessa limitação.
-
Classificação Binária: O perceptron básico é projetado para classificação binária.
- Sem Estimativas de Probabilidade: O perceptron produz decisões binárias (0 ou 1) sem fornecer estimativas de probabilidade.
- Sensibilidade à Taxa de Aprendizado: A escolha da taxa de aprendizado pode afetar significativamente o processo de treinamento.
Playground Interativo: Treine um Perceptron
Clique na área abaixo para adicionar pontos (clique normal = Classe A, Shift+clique = Classe B). O perceptron atualiza os pesos automaticamente a cada época usando a regra de aprendizado de Rosenblatt.
Resumo
O algoritmo de treinamento do perceptron é um processo simples e iterativo que ajusta pesos e bias para minimizar erros de classificação em um dataset linearmente separável. Envolve inicializar parâmetros, calcular predições, calcular erros e atualizar pesos com base na regra de aprendizado do perceptron. Embora limitado a classificação binária e dados linearmente separáveis, é um conceito fundamental para entender redes neurais mais complexas.
-
McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics, 5(4), 115-133. doi:10.1007/BF02478259 ↩
-
Rosenblatt, F. (1958). The Perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386-408. doi:10.1037/h0042519 ↩
-
Jurafsky, D., & Martin, J. H. (2025). Speech and Language Processing. ↩
-
Hebb, D. O. (1949). The organization of behavior: A neuropsychological theory. John Wiley & Sons. doi.org/10.1002/sce.37303405110 ↩
-
Minsky, M., & Papert, S. (1969). Perceptrons: An introduction to computational geometry. MIT Press. ↩