18. VAE
Autoencoders
Autoencoders (AEs) são redes neurais projetadas para aprender:
- codificações eficientes de dados de entrada, comprimindo-os em uma representação de menor dimensão, e então;
- reconstruindo-os de volta à forma original.
Autoencoders consistem em dois componentes principais:
-
um encoder, que comprime dados de entrada em uma representação de menor dimensão conhecida como espaço latente ou código. Este espaço latente, frequentemente chamado de embedding, visa reter o máximo de informação possível, permitindo ao decoder reconstruir os dados com alta precisão. Se denotarmos nossos dados de entrada como \( x \) e o encoder como \( E \), então a representação do espaço latente de saída, \( s \), seria \( s=E(x) \).
-
um decoder, que reconstrói os dados de entrada originais aceitando a representação do espaço latente \( s \). Se denotarmos a função decoder como \( D \) e a saída do decoder como \( o \), então podemos representar o decoder como \( o = D(s) \).
Tanto o encoder quanto o decoder são tipicamente compostos de uma ou mais camadas, que podem ser totalmente conectadas, convolucionais ou recorrentes, dependendo da natureza dos dados de entrada e da arquitetura do autoencoder.1 O processo completo do autoencoder pode ser resumido como:
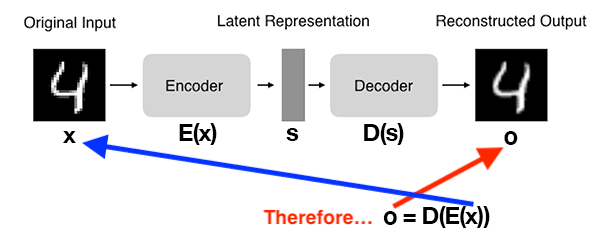
Uma ilustração da arquitetura de autoencoders. Fonte: 1.
Tipos de Autoencoder
Existem vários tipos de autoencoders, cada um com suas particularidades:
Autoencoders Vanilla
Autoencoders vanilla são camadas totalmente conectadas para encoder e decoder. Funcionam para comprimir informações de entrada e são aplicados em dados simples.
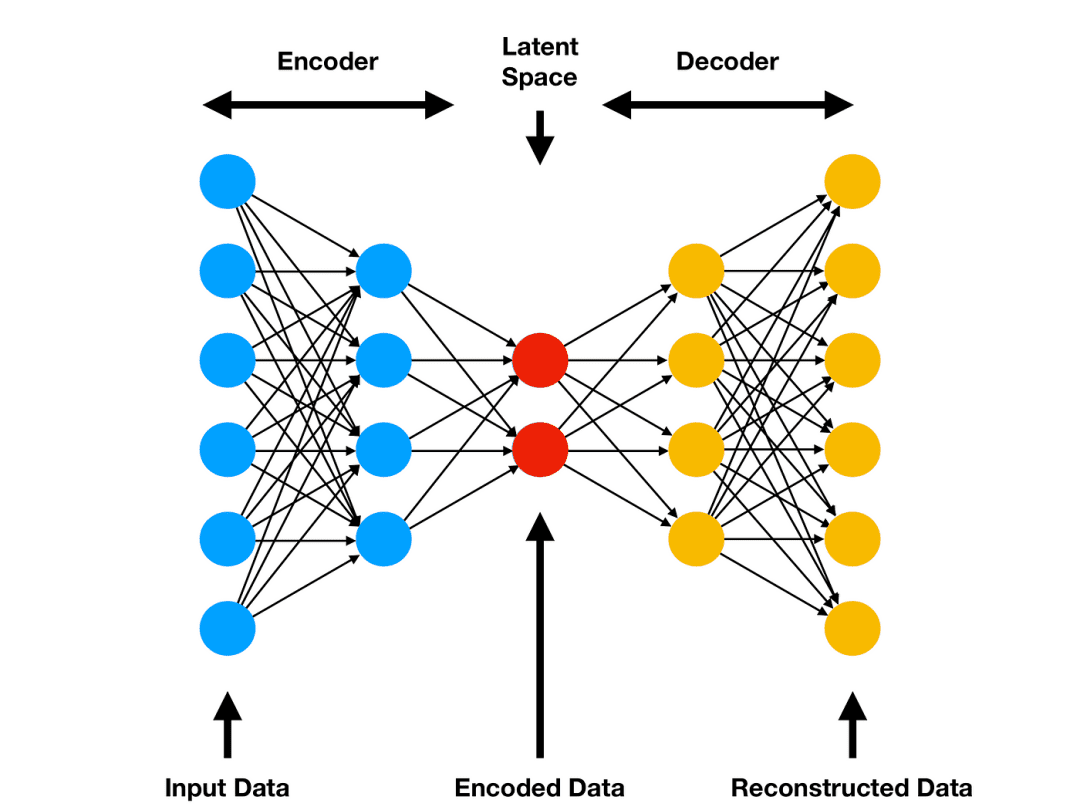
Tanto o encoder quanto o decoder são redes totalmente conectadas. O encoder mapeia os dados de entrada para o espaço latente (espaço comprimido — dados codificados). O decoder mapeia os dados do espaço latente para a saída (dados reconstruídos). Fonte: 1.
O Espaço Latente é uma representação comprimida dos dados de entrada. A dimensionalidade do espaço latente é tipicamente muito menor do que a dos dados de entrada, o que força o autoencoder a aprender uma representação compacta que captura as features mais importantes dos dados.
Autoencoders Convolucionais
Em autoencoders convolucionais, o encoder e o decoder são redes neurais baseadas em Redes Neurais Convolucionais. Portanto, a abordagem é mais intensiva para lidar com dados de imagem.
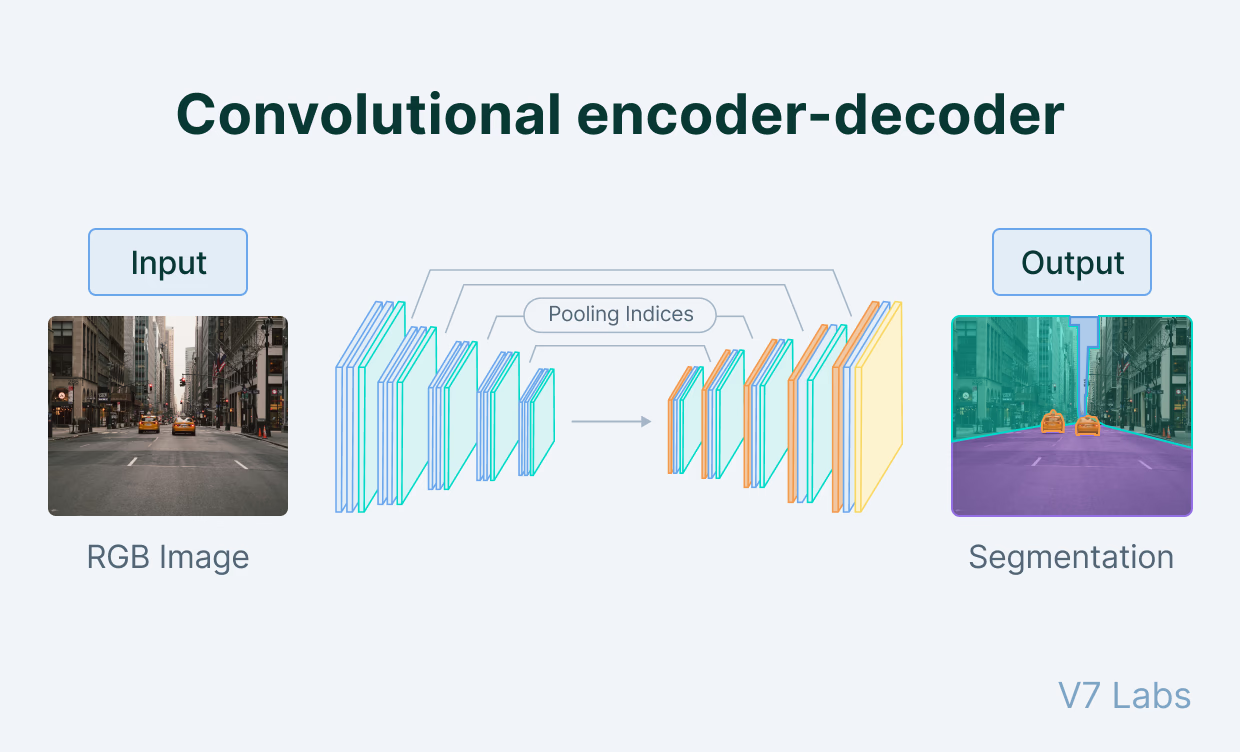
Em autoencoders convolucionais, o encoder e o decoder são baseados em CNNs. Esta arquitetura é particularmente eficaz para dados de imagem, pois pode capturar hierarquias e padrões espaciais. Fonte: 2.
Autoencoders Variacionais
Autoencoders Variacionais (VAEs) são modelos generativos que aprendem a codificar dados em um espaço latente de menor dimensão e depois decodificá-los de volta ao espaço original. VAEs podem gerar novas amostras a partir da distribuição latente aprendida, tornando-os ideais para geração de imagens e transferência de estilo.
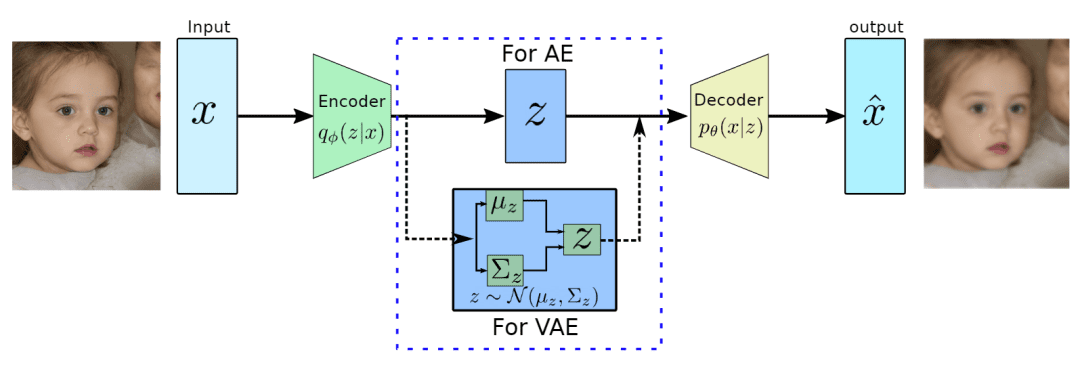
Um VAE mapeia dados de entrada \( \mathbf{x} \) para o espaço latente \( \mathbf{z} \) e então os reconstrói de volta ao espaço original \( \mathbf{\hat{x}} \) (saída). Fonte: 2.
VAEs foram introduzidos em 2013 por Diederik et al. - Auto-Encoding Variational Bayes.
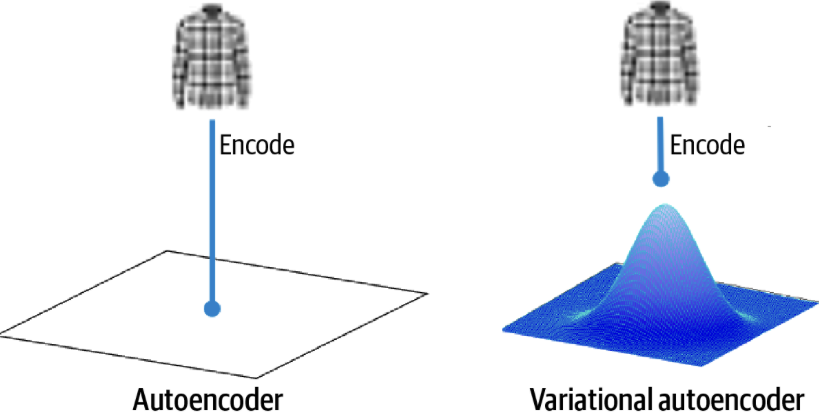
Figura: Comparação entre um Autoencoder padrão e um Autoencoder Variacional (VAE). Em um Autoencoder padrão, o encoder mapeia dados de entrada \( \mathbf{x} \) para uma representação latente fixa \( \mathbf{z} \). Em contraste, um VAE codifica os dados de entrada em uma distribuição sobre o espaço latente, tipicamente modelada como uma distribuição gaussiana com média \( \mu \) e desvio padrão \( \sigma \). Dataset: Fashion-MNIST. Fonte: 3.
Características Principais dos VAEs
VAEs têm a capacidade de aprender espaços latentes suaves e contínuos, o que permite interpolação significativa entre pontos de dados. Isso é particularmente útil em aplicações como geração de imagens. A natureza probabilística dos VAEs também ajuda a regularizar o espaço latente, prevenindo overfitting.
Aspectos dos VAEs incluem:
-
Regularização e Continuidade: O espaço latente nos VAEs é regularizado para seguir uma distribuição a priori (geralmente uma distribuição normal padrão), encorajando um espaço latente contínuo e suave.
-
Simplicidade na Amostragem: VAEs podem gerar novas amostras simplesmente amostrando do espaço latente da distribuição gaussiana.
-
Truque de Reparametrização: Para habilitar a retropropagação pelo processo de amostragem estocástica, os VAEs empregam o truque de reparametrização, expressando a variável latente amostrada \( \mathbf{z} \) como uma função determinística de \( \mathbf{x} \) e uma variável de ruído aleatório \( \mathbf{\epsilon} \).
-
Espaço Latente Equilibrado: O termo de divergência KL na função de perda do VAE encoraja o espaço latente aprendido a ser similar à distribuição a priori.
Treinamento de VAEs
VAEs usam a Divergência de Kullback-Leibler (KL) em sua função de perda, que mede a diferença entre a distribuição latente aprendida e a distribuição a priori. A função de perda é uma combinação da perda de reconstrução e do termo de divergência KL.
Queremos encontrar uma distribuição \( p(z|x) \) usando o Teorema de Bayes:
Mas o problema é que \(p(x)\) é intratável:
Esta integral frequentemente é intratável. Portanto, aproximamos com uma distribuição variacional \( q(z|x) \), que é mais fácil de calcular, minimizando a divergência KL entre \( q(z|x) \) e \( p(z|x) \):
Por simplificação, isto equivale ao seguinte problema de maximização:
Portanto, a função de perda para treinar um VAE pode ser expressa como:

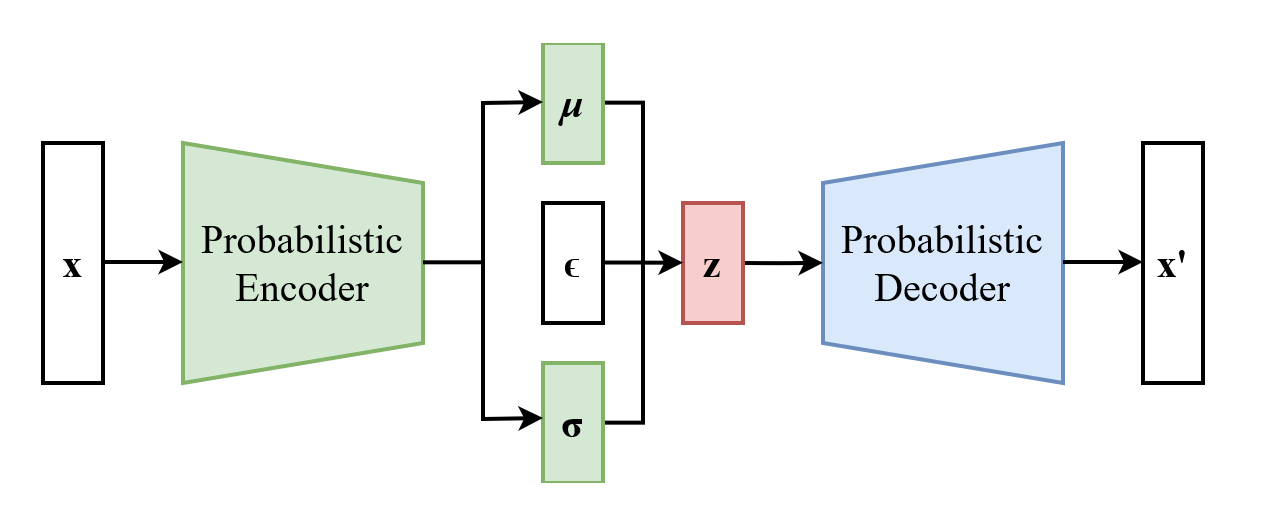
Figura: Arquitetura básica de um Autoencoder Variacional (VAE). O encoder mapeia dados de entrada \( \mathbf{x} \) para uma representação latente \( \mathbf{z} \), e o decoder reconstrói \( \mathbf{x'} \) a partir de \( \mathbf{z} \). Fonte: Wikipedia
Truque de Reparametrização
O truque de reparametrização é uma inovação chave que permite a retropropagação eficiente através das camadas estocásticas de um VAE. Em vez de amostrar \( z \) diretamente de \( q(z|x) \), expressamos \( z \) como uma função determinística de \( x \) e algum ruído \( \epsilon \) retirado de uma distribuição simples (ex: gaussiana):
onde \( \mu \) e \( \sigma \) são as saídas de média e desvio padrão do encoder. Esta transformação permite a retropropagação através da rede enquanto mantém a natureza estocástica da variável latente.
Simulação Numérica
VAE - Autoencoder Variacional
A Variational Autoencoder (VAE) encodes input data into a probabilistic latent space (defined by mean μ and log-variance log(σ²)) and decodes it back to reconstruct the input. The latent space is sampled using the reparameterization trick for differentiability. The loss combines reconstruction error (MSE) and KL divergence to regularize the latent distribution toward a standard normal.
For this numerical example, we've scaled up to:
- Input dimension: 4 (e.g., a vector like
[1.0, 2.0, 3.0, 4.0]) - Latent dimension: 2
- Output dimension: 4 (reconstruction of input)
- Hidden layer size: 8 (for both encoder and decoder, to add capacity)
The model uses PyTorch with random initialization (seeded at 42 for reproducibility). All calculations are shown step-by-step, including matrix multiplications where relevant. Weights and biases are explicitly listed below.
Model Architecture
---
config:
layout: elk
---
flowchart LR
subgraph Input["Input"]
direction TB
x1["x1"]
x2["x2"]
x3["x3"]
x4["x4"]
end
subgraph Hidden1["Hidden1"]
direction TB
h11["h11"]
h12["h12"]
h13["h13"]
h14["h14"]
h15["h15"]
h16["h16"]
h17["h17"]
h18["h18"]
end
subgraph Encoder["Encoder"]
direction LR
Input
Hidden1
end
subgraph Latent["Latent"]
l1["l1"]
l2["l2"]
end
subgraph Hidden2["Hidden2"]
direction TB
h21["h21"]
h22["h22"]
h23["h23"]
h24["h24"]
h25["h25"]
h26["h26"]
h27["h27"]
h28["h28"]
end
subgraph Output["Output"]
direction TB
y1["y1"]
y2["y2"]
y3["y3"]
y4["y4"]
end
subgraph Decoder["Decoder"]
direction LR
Hidden2
Output
end
x1 --- h11 & h12 & h13 & h14 & h15 & h16 & h17 & h18
x2 --- h11 & h12 & h13 & h14 & h15 & h16 & h17 & h18
x3 --- h11 & h12 & h13 & h14 & h15 & h16 & h17 & h18
x4 --- h11 & h12 & h13 & h14 & h15 & h16 & h17 & h18
h11 --- l1 & l2
h12 --- l1 & l2
h13 --- l1 & l2
h14 --- l1 & l2
h15 --- l1 & l2
h16 --- l1 & l2
h17 --- l1 & l2
h18 --- l1 & l2
l1 --- h21 & h22 & h23 & h24 & h25 & h26 & h27 & h28
l2 --- h21 & h22 & h23 & h24 & h25 & h26 & h27 & h28
h21 --- y1 & y2 & y3 & y4
h22 --- y1 & y2 & y3 & y4
h23 --- y1 & y2 & y3 & y4
h24 --- y1 & y2 & y3 & y4
h25 --- y1 & y2 & y3 & y4
h26 --- y1 & y2 & y3 & y4
h27 --- y1 & y2 & y3 & y4
h28 --- y1 & y2 & y3 & y4A[Input Data] -->|Encode| B[Latent Space]; B -->|Decode| C[Reconstructed Data]; B --> D[Mean (μ)]; B --> E[Log Variance (log σ²)]; D --> F[Sampling (z = μ + σ * ε)]; E --> F; F --> C;
-
Encoder:
- Linear (fc1): 4 inputs → 8 hidden units, followed by ReLU.
- Linear to μ (fc_mu): 8 → 2.
- Linear to logvar (fc_logvar): 8 → 2.
-
Latent: Sample z from N(μ, σ²) using reparameterization trick.
-
Decoder:
- Linear (fc_dec1): 2 latent → 8 hidden units, followed by ReLU.
- Linear to output (fc_dec2): 8 → 4 (no final activation, assuming Gaussian output for simplicity).
-
Loss: Summed MSE for reconstruction + KL divergence (without β annealing).
Weights and Biases
All parameters are initialized randomly (via torch.manual_seed(42)). Here they are:
Encoder
-
fc1.weight (encoder input to hidden, shape [8, 4]):
-
fc1.bias (shape [8]):
-
fc_mu.weight (hidden to μ, shape [2, 8]):
-
fc_mu.bias (shape [2]):
-
fc_logvar.weight (hidden to logvar, shape [2, 8]):
-
fc_logvar.bias (shape [2]):
Decoder
-
fc_dec1.weight (latent to decoder hidden, shape [8, 2]):
-
fc_dec1.bias (shape [8]):
-
fc_dec2.weight (decoder hidden to output, shape [4, 8]):
-
fc_dec2.bias (shape [4]):
Forward Pass
-
Input:
(batch size 1, dim 4).
-
Encoding to Hidden Layer:
-
Compute pre-ReLU: fc1(x) = fc1.weight @ x^T + fc1.bias.
- This is a matrix multiplication: Each row of fc1.weight dotted with x, plus bias.
- Result (pre-ReLU):
- After ReLU (non-negative): (note: last two are zeroed by ReLU).
-
-
Compute Mean (μ) in Latent Space:
- μ = fc_mu.weight @ hidden^T + fc_mu.bias.
- Result:
- This is the mean of the 2D latent Gaussian.
- μ = fc_mu.weight @ hidden^T + fc_mu.bias.
-
Compute Log-Variance (logvar) in Latent Space:
-
logvar = fc_logvar.weight @ hidden^T + fc_logvar.bias.
- Result:
- Variance σ² = exp(logvar):
-
-
Latent Space: Sampling z (Reparameterization Trick):
-
std (σ) = exp(0.5 * logvar):
-
ε ~ N(0, 1) (seeded random):
-
\( z = \mu + std * \epsilon \)
-
Result:
-
-
Decoding to Reconstructed Output:
- Decoder: ReLu( fc_dec1.weight @ z^T + fc_dec1.bias ).
- pre-ReLU:
- After ReLU:
-
recon_x = fc_dec2.weight @ decoder_hidden^T + fc_dec2.bias.
-
Result:
-
- Decoder: ReLu( fc_dec1.weight @ z^T + fc_dec1.bias ).
Loss Calculation
-
Reconstruction Loss (MSE):
Sum over dimensions of \( (x - \hat{x})^2 ≈ 31.100958927489703 \)
-
KL Divergence:
\[ \text{KL} = -0.5 * \sum \left(1 + \text{logvar} - \mu^2 - \exp(\text{logvar})\right) \approx 0.40952290104490313 \] -
Total Loss:
\[ \text{Loss} = \text{MSE} + \text{KL} \approx 31.510481828534605 \]
Backward Pass
The backward pass computes gradients via autograd (chain rule from loss back through the network). This enables training by updating weights (e.g., via SGD). Gradients are zero-initialized before .backward().
After loss.backward(), key gradients \( \displaystyle \frac{\partial \text{Loss}}{\partial \text{param}} \) are:
Decoder
-
fc_dec2.weight.grad (shape [4, 8]):
\[ \displaystyle \frac{\partial \text{L}}{\partial \text{fc_dec2.weight}} \] -
fc_dec2.bias.grad (shape [4]):
-
fc_dec1.weight.grad (shape [8, 2]):
[ [ 0.0000, -0.0000], [ 2.7321, -2.6684], [ 0.0000, -0.0000], [ 2.6066, -2.5459], [-1.7850, 1.7434], [ 2.1179, -2.0685], [ 0.0000, -0.0000], [ 0.0000, -0.0000] ]- Primarily from MSE, backpropagated through decoder.
-
fc_dec1.bias.grad (shape [8]):
Encoder
-
fc_mu.weight.grad (shape [2, 8]):
- Includes ∂KL/∂μ ≈ μ (pulling toward 0) + flow from MSE via z. -
fc_mu.bias.grad (shape [2]):
-
fc_logvar.weight.grad (shape [2, 8]):
- From ∂KL/∂logvar ≈ 0.5*(exp(logvar) - 1) + MSE flow. -
fc_logvar.bias.grad (shape [2]):
-
fc1.weight.grad (shape [8, 4]):
[ [ 0.2735, 0.5470, 0.8204, 1.0939], [-0.2724, -0.5448, -0.8172, -1.0896], [ 0.5339, 1.0679, 1.6018, 2.1358], [ 1.2016, 2.4032, 3.6049, 4.8065], [ 0.7601, 1.5201, 2.2802, 3.0403], [-0.5289, -1.0578, -1.5868, -2.1157], [ 0.0000, 0.0000, 0.0000, 0.0000], [ 0.0000, 0.0000, 0.0000, 0.0000] ]- These flow from both MSE (via reconstruction) and KL (via μ/logvar). Zeros in last rows due to ReLU zeroing those hidden units.
-
fc1.bias.grad (shape [8]):
These gradients would update parameters in training (e.g., param -= lr * grad). Note zeros where ReLU gates flow. This example uses a single pass; real training iterates over datasets. If you change the seed, input, or dimensions, values will differ, but the process remains identical.
Adicional
Relação entre Log Variância e Desvio Padrão
Relação entre Log Variância e Desvio Padrão
- Nos VAEs, o encoder produz a média \( \mu \) e a log variância \( \log(\sigma^2) \) da distribuição do espaço latente.
- O desvio padrão \( \sigma \) pode ser derivado da log variância usando a relação:
- Esta transformação garante estabilidade numérica e positividade da variância durante o treinamento.
1. Definitions
For a random variable ( x ) that follows a normal distribution:
where:
- \( \mu \): mean
- \( \sigma^2 \): variance
- \( \sigma \): standard deviation
2. Log variance
Often, instead of directly predicting or storing the variance \( \sigma^2 \) or standard deviation \( \sigma \), models work with the log variance:
3. Relationship between log variance and std
From the above definition:
Taking the square root to get the standard deviation:
So:
and conversely,
4. Why use log variance?
It’s common in neural nets because:
- It ensures the variance is always positive (since \( e^x > 0 \)).
- It’s numerically more stable when optimizing.
- It allows unconstrained outputs from the network (no need to force positivity).
Summary
| Quantity | Expression | In terms of log_var |
|---|---|---|
| Variance | \( \sigma^2 \) | \( e^{\text{log_var}} \) |
| Std. deviation | \( \sigma \) | \( e^{\frac{1}{2}\text{log_var}} \) |
| Log variance | \( \text{log_var} \) | \( 2 \log(\sigma) \) |