Introdução Data Lakes
Introdução
No cenário atual, o engenheiro de dados nem sempre irá ingerir tabelas bem definidas. Logs de aplicação, eventos de sensores, cliques, imagens e textos competem por espaço nas arquiteturas de dados. Uma outra alternativa para armazenar esses dados é o Data Lake.
Um Data Lake é um repositório de armazenamento de grande escala que mantém dados brutos no formato nativo.
Sua popularização cresceu por volta de 2010, quando data warehouses relacionais passaram a sofrer com volume, variedade e velocidade de dados semi ou não estruturados.
Motivação para o surgimento do Data Lake!
Como guardar tudo isso agora, mesmo sem saber ainda todos os usos futuros?
Um Data Lake aceita múltiplos formatos de dados (estruturado, semi-estruturado, não estruturado) sem impor um esquema antecipado. Ele funciona como um repositório centralizado que pode conter tanto cópias não processadas de dados de sistemas de origem, (sensores, logs, sistemas de gestão), quanto informações já transformadas para uso em dashboards, análises avançadas ou treinamento de modelos.
Por que não só Data Warehouse?
O warehouse tradicional parte de um modelo pré-definido (schema-on-write). Isso exige decidir colunas, tipos e regras antes de carregar, o que pode atrasar a ingestão e limitar a flexibilidade para novos casos de uso.
O Data Lake inverte essa lógica: armazena agora, interpreta depois (schema-on-read). Assim, a modelagem e padronização ficam próximas do momento de consumo ou de etapas de refinamento.
Exercise
Answer
- Logs de servidores web, que podem ter formatos variados e mudanças frequentes.
- Dados de sensores IoT, que geram grandes volumes de dados em formatos não estruturados.
Características
Como características essenciais, um Data Lake geralmente apresenta:
- Store first: ingestão rápida copiando arquivos (ou dados em fluxo) quase como chegam.
- Escalabilidade horizontal: usando armazenamento de objetos (ex.: S3) com custo baixo, ou seja, foco em armazenar grandes volumes de dados de forma econômica.
- Neutralidade de computação: tem capacidade de processar e analisar dados usando diferentes engines de computação e ferramentas analíticas, sem ficar restrito a uma única tecnologia.
- Retenção histórica: buscar manter versões com histórico dos dados brutos pelo tempo definido em política de retenção, que considera requisitos legais, valor analítico e custo de armazenamento.
Observe que nenhuma dessas características garante valor por si só. Sem contexto e organização, vira apenas um repositório barato.
Exercise
Answer
Reter dados brutos permite reprocessar os dados originais com as correções necessárias, garantindo que qualquer erro na transformação anterior possa ser corrigido sem perda de informação.
Camadas Lógicas
Para evitar que o Data Lake se torne um pântano (data swamp), é necessário prover uma organização mínima.
Isto pode ser obtido ao aplicar uma separação simples de camadas.
Uma primeira divisão possível é separar dados brutos de dados processados.
| Camada | Objetivo | Exemplo de conteúdo |
|---|---|---|
raw |
Captura dos dados | JSON, CSV original, logs, imagens |
processed |
Limpeza, padronização, integração | Colunas tipadas, normalização de datas, arquivos de formato colunar (Parquet) |
Uma melhor organização pode ser obtida com a separação em três camadas.
| Camada | Objetivo | Exemplo de conteúdo |
|---|---|---|
raw (Bronze) |
Captura integral e imutável | JSON de eventos, CSV original, logs, imagens |
cleansed (Silver) |
Limpeza, padronização, integração | Colunas tipadas, normalização de datas, arquivos de formato colunar (Parquet) |
presentation (Gold) |
Lógica de negócio pronta para consumo | Tabelas derivadas, fatos e dimensões, conjuntos agregados |
Info!
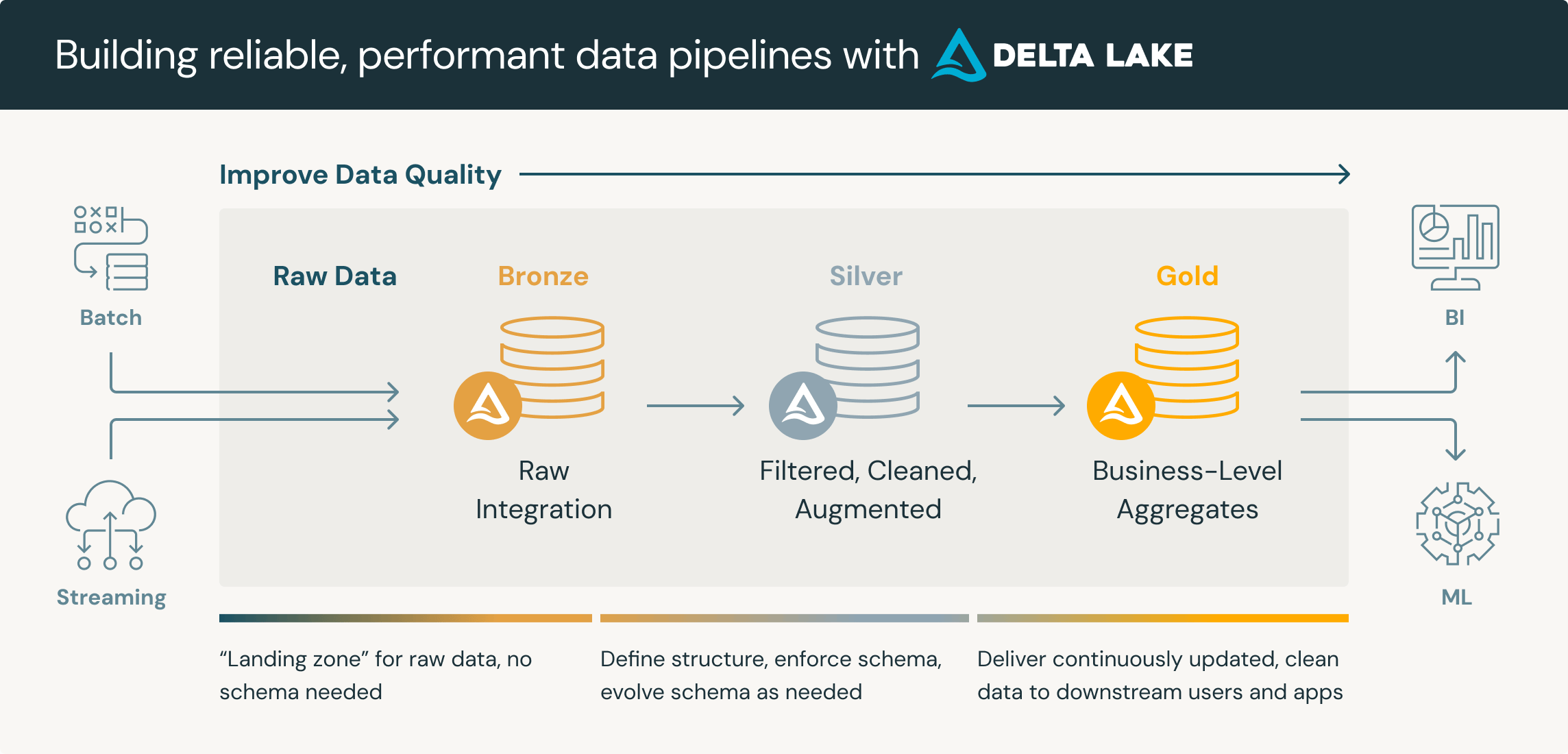
Apesar de não ser a organização formal, a organização em três camadas (Bronze, Silver, Gold) é um padrão emergente, e bastante utilizada na prática.
Na prática vocês verão essas camadas mapeadas em prefixos de caminhos (ex.: s3://meu-data-lake/raw/...).
Arquitetura Medallion
Este padrão de camadas (Bronze, Silver, Gold) é conhecido como Medallion Architecture e foi popularizado pela Databricks.
 Fonte: Adaptado de Databricks
Fonte: Adaptado de Databricks
{kind=link}
Caso queira se aprofundar, veja este artigo da Databricks
Exercise
Answer
- Conversão de tipos de dados (ex.: transformar strings em datas ou números).
- Remoção de duplicatas e tratamento de valores nulos.
- Normalização de formatos (ex.: padronizar datas para um formato único).
Vantagem x Risco
Um Data Lake geralmente oferece custo baixo por terabyte e flexibilidade para novos usos. Entretanto, sem governança mínima (nomenclatura, controle de versões de schema, sem metadados ricos, políticas de retenção e padrões de qualidade) ele degrada em um conjunto caótico de pastas!
Data Swamp
Usuários deixam de confiar e criam cópias paralelas.
Checagem Rápida
Exercise
Answer
- Schema-on-write exige definir o esquema antes de armazenar os dados, o que pode atrasar a ingestão, mas garante consistência imediata.
- Schema-on-read permite armazenar dados brutos rapidamente, adiando a definição do esquema para o momento da leitura, o que acelera a disponibilização inicial dos dados.
Question
Answer
Falso. Arquivos Parquet são amplamente utilizados em Data Lakes por serem eficientes em termos de armazenamento e consulta.
Exercise
Nesta introdução, definimos Data Lake, justificamos sua existência, diferenciamos de um warehouse, discutimos camadas e riscos. Com isso, vocês estão prontos para experimentar na prática! Siga para a próxima seção.