04 - Medição de desempenho¶
Apesar de podermos medir o tempo que nosso programa demora usando o comando time, não conseguimos nenhuma informação importante de qual parte do programa está consumindo mais tempo. Este processo de dissecar um programa e entender exatamente qual parte demora quanto é chamada de Profiling.
Software
Para esta aula precisaremos dos seguintes pacotes instalados.
valgrind- ferramenta de análise de código executávelkcachegrind- visualizador de resultados dovalgrind
Warm-up: O problema da soma de uma matriz¶
O código abaixo apresenta duas formas de realizar a soma de todos os elementos de uma matriz.
Compile o código e execute.
Você sabe dizer qual a diferença de naive_sum e improved_sum?
#include<iostream>
#include<algorithm>
using namespace std;
constexpr int M = 2048;
constexpr int N = 2048;
double naive_sum(const double a[][N]){
double sum = 0.0;
for(int j = 0; j < N; ++j) {
for(int i = 0; i < M; ++i)
sum += a[i][j];
}
return sum;
}
double improved_sum(const double a[][N]) {
double sum = 0.0;
for(int i = 0; i < M; ++i)
for(int j = 0; j < N; ++j)
sum +=a[i][j];
return sum;
}
int main() {
static double a[M][N];
fill_n(&a[0][0], M*N, 1.0 / (M*N));
cout << naive_sum(a) << endl;
static double b[M][N];
fill_n(&b[0][0], M*N, 1.0 / (M*N));
cout << improved_sum(b) << endl;
return 0;
}
Vamos usar o Valgrind para verificar se há diferenças entre naive_sum e improved_sum.
Supondo que o seu arquivo se chama sum.cpp execute:
g++ -Wall -O3 -g sum.cpp -o sum
E execute então programa via valgrind:
valgrind --tool=callgrind ./sum
O valgrind irá retornar algo como:
==3079146== Callgrind, a call-graph generating cache profiler
==3079146== Copyright (C) 2002-2017, and GNU GPL'd, by Josef Weidendorfer et al.
==3079146== Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
==3079146== Command: ./sum
==3079146==
==3079146== For interactive control, run 'callgrind_control -h'.
1
1
==3079146==
==3079146== Events : Ir
==3079146== Collected : 50553796
==3079146==
==3079146== I refs: 50,553,796
Onde 3079146 é o PID da execução. Na sua máquina será um outro valor. Ele também gerou um arquivo callgrind.out.{PID}.
Execute a ferramenta callgrind_annotate para verificar o resultado do profiling.
callgrind_annotate callgrind.out.3079146 sum.cpp
E seu output será como segue:
--------------------------------------------------------------------------------
Profile data file 'callgrind.out.3079146' (creator: callgrind-3.15.0)
--------------------------------------------------------------------------------
I1 cache:
D1 cache:
LL cache:
Timerange: Basic block 0 - 10863316
Trigger: Program termination
Profiled target: ./sum (PID 3079146, part 1)
Events recorded: Ir
Events shown: Ir
Event sort order: Ir
Thresholds: 99
Include dirs:
User annotated: sum.cpp
Auto-annotation: off
--------------------------------------------------------------------------------
Ir
--------------------------------------------------------------------------------
50,553,796 PROGRAM TOTALS
--------------------------------------------------------------------------------
Ir file:function
--------------------------------------------------------------------------------
31,479,818 sum.cpp:main [/home/user/andre/profile/sum]
16,777,221 /usr/include/c++/9/bits/stl_algobase.h:main
948,840 /build/glibc-eX1tMB/glibc-2.31/elf/dl-lookup.c:_dl_lookup_symbol_x [/usr/lib/x86_64-linux-gnu/ld-2.31.so]
554,233 /build/glibc-eX1tMB/glibc-2.31/elf/dl-lookup.c:do_lookup_x [/usr/lib/x86_64-linux-gnu/ld-2.31.so]
273,488 /build/glibc-eX1tMB/glibc-2.31/elf/../sysdeps/x86_64/dl-machine.h:_dl_relocate_object
117,179 /build/glibc-eX1tMB/glibc-2.31/elf/dl-lookup.c:check_match [/usr/lib/x86_64-linux-gnu/ld-2.31.so]
--------------------------------------------------------------------------------
-- User-annotated source: sum.cpp
--------------------------------------------------------------------------------
Ir
. #include<iostream>
. #include<algorithm>
. using namespace std;
.
. constexpr int M = 2048;
. constexpr int N = 2048;
.
. double naive_sum(const double a[][N]){
1 double sum = 0.0;
6,144 for(int j = 0; j < N; ++j) {
12,587,008 for(int i = 0; i < M; ++i)
4,194,304 sum += a[i][j];
. }
. return sum;
. }
.
. double improved_sum(const double a[][N]) {
4,097 double sum = 0.0;
8,192 for(int i = 0; i < M; ++i)
4,194,304 for(int j = 0; j < N; ++j)
10,485,760 sum +=a[i][j];
. return sum;
. }
.
5 int main() {
. static double a[M][N];
. fill_n(&a[0][0], M*N, 1.0 / (M*N));
. cout << naive_sum(a) << endl;
. static double b[M][N];
. fill_n(&b[0][0], M*N, 1.0 / (M*N));
. cout << improved_sum(b) << endl;
. return 0;
6 }
--------------------------------------------------------------------------------
Ir
--------------------------------------------------------------------------------
31,479,821 events annotated
O que você pode dizer sobre o desempenho do programa? Por que há diferença de instruction fetch (IR) entre naive_sum e improved_sum?
Tip
Dica: Verifique a discussão no StackOverflow sobre isso. Neste link https://stackoverflow.com/questions/9936132/why-does-the-order-of-the-loops-affect-performance-when-iterating-over-a-2d-arra
Visualização gráfica¶
Muitas vezes o output do valgrind é suficiente para a nossa análise. Todavia, é possível também obter visualizações gráficas do número de chamadas das funções. Há uma ferramenta bem interessante, desenvolvida em Python, denominada gprof2dot. Essa ferramenta converte dados de perfil de desempenho, gerados por ferramentas como o Callgrind do Valgrind, em gráficos de chamadas visualmente compreensíveis. Ao processar os resultados de profiling, ele cria um gráfico que representa as interações entre funções, evidenciando as chamadas mais onerosas e ajudando a identificar gargalos de desempenho em um programa. Isso permite uma análise mais intuitiva e abrangente das relações entre as funções e a alocação de recursos computacionais, auxiliando na otimização de códigos e no aprimoramento da eficiência do software.
Vamos fazer um teste nessa ferramenta? Para isso, você vai precisar instalar a bibliteca graphviz (com apt-get install graphviz, por exemplo) e também a biblioteca gprof2dot do Python (com pip install gprof2dot).
Considere o seguinte código em C++ para analisarmos com essa ferramenta:
#include <iostream>
#include <cmath>
#include <chrono>
void heavyCalculation() {
for (int i = 0; i < 100000; ++i) {
double result = std::sqrt(static_cast<double>(i));
}
}
void intermediateFunction() {
for (int i = 0; i < 1000; ++i) {
heavyCalculation();
}
}
void mainFunction() {
for (int i = 0; i < 5; ++i) {
intermediateFunction();
}
}
int main() {
auto start = std::chrono::high_resolution_clock::now();
mainFunction();
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "Time taken: " << duration.count() << " milliseconds" << std::endl;
return 0;
}
Nesse código, temos três funções:
-
heavyCalculation: Uma função que realiza um grande número de operações matemáticas (cálculos de raiz quadrada) em um loop.
-
intermediateFunction: Chama a função heavyCalculation repetidamente para criar um cenário onde a função intermediária é onerosa.
-
mainFunction: Chama a função intermediária várias vezes.
Ao executar esse código, você deve obter um tempo de execução considerável, já que o loop dentro de heavyCalculation é repetido muitas vezes. Isso deve gerar um perfil de desempenho interessante quando analisado com o gprof2dot.py.
Ao compilar, use a opção -O0, para que o compilador não otimize as chamadas recorrentes e possamos visualizar melhor nosso grafo.
Supondo que seu código foi salvo com o nome profile.cpp, execute os seguintes comandos:
g++ -Wall -O0 -g profile.cpp -o profile
Na sequencia, execute o valgrind:
valgrind --tool=callgrind ./profile
Neste caso, um possível output seria:
==9228== Callgrind, a call-graph generating cache profiler
==9228== Copyright (C) 2002-2017, and GNU GPL'd, by Josef Weidendorfer et al.
==9228== Using Valgrind-3.18.1 and LibVEX; rerun with -h for copyright info
==9228== Command: ./profile
==9228==
==9228== For interactive control, run 'callgrind_control -h'.
Time taken: 243965 milliseconds
==9228==
==9228== Events : Ir
==9228== Collected : 10002410933
==9228==
==9228== I refs: 10,002,410,933
Por fim, execute a gprof2dot:
!gprof2dot -n0.1 -f callgrind callgrind.out.9228 | dot -Tsvg -o output.svg
Você deve obter um grafo similar ao abaixo:

Distância: Euclides ingênuo¶
Compile o código-fonte da implementação ingênua que fizemos na aula passada, com profiling habilitado para medir os tempos de execução.
g++ -g euclides-ingenuo.cpp -o euclides-ingenuo
Após este passo, execute o programa usando o valgrind com as opções abaixo.
valgrind --tool=callgrind ./seu_exec < entrada > saida
Para mostrar os resultados usando o kcachegrind usamos o seguinte comando.
kcachegrind callgrind.out.(pid aqui)
O que tomou mais tempo de execução da versão ingênua?
Medindo os tempos no seu próprio programa¶
Você vai perceber, ao executar a atividade anterior, que boa parte do tempo é gasto mostrando a saída no terminal. Isto nos leva à primeira conclusão da atividade de hoje:
Entrada e saída de dados são operações muito lentas
Example
Faça o teste da demonstração em seu próprio programa e anote abaixo, para as duas versões de calcula_distancias,
- o tempo relativo de execução
- o número absoluto de instruções executadas
Question
O número absoluto de intruções executadas diminuiu significativamente depois de nossa otimização? Teoricamente só calculamos metade da matriz, esse número é quase metade da versão não otimizada? Você consegue dizer por que?
Resposta
Deve ter havido uma diminuição, mas não chega nem perto de metade. Isso ocorre por várias razões:
- nosso
forduplo continua percorrendo a matriz inteira, apesar de só fazer o cálculo em metade das posições. - alocamos a matriz elemento a elemento enquanto fazemos os cálculos.
Com isso em mente, vamos agora otimizar a função calcula_distancias. Já sabemos que o efeito no tempo final não será grande. Nosso objetivo então será verificar a seguinte afirmação.
Dois algoritmos de mesma complexidade computacional podem ter tempos de execução muito diferentes
Question
A resposta da questão anterior indica que só usar um if para evitar o cálculo repetido não é suficiente. Precisamos efetivamente fazer um for que percorre só metade da matriz. Supondo que a matriz já esteja inteira alocada, escreva em pseudo-código como fazê-lo.
Resposta
para i=1..N:
para j=i..N:
DX = X[i] - X[j]
DY = Y[i] - Y[j]
DIST = sqrt(DX*DX + DY*DY)
D[i,j] = DIST
D[j,i] = DIST
Matrizes (versão 2)¶
Nossa implementação usando vector<vector<double>> tem um problema sério: ela aloca elemento a elemento uma estrutura grande que já sabemos o tamanho de início. Seria muito melhor se pudéssemos alocar todas as N^2 posições da matriz de uma só vez!
Fazemos isso trabalhando com um layout de memória contínuo. Ou seja, armazenaremos a matriz linha a linha como um único vetor de tamanho n*n. Temos várias vantagens:
- tempo de alocação de memória é reduzido, já que só fazemos uma chamada
- podemos acessar qualquer posição a qualquer momento
- melhor desempenho de cache
A figura abaixo exemplifica esse layout de memória:
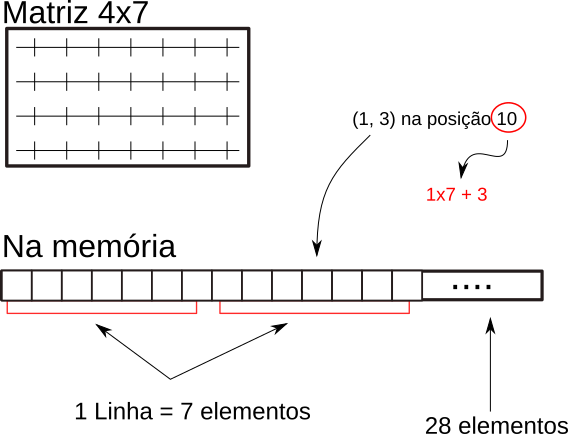
Question
Em uma matriz de tamanho 4x7 (4 linhas, 7 colunas), qual é o elemento do vetor que representa a posição 2x5 (linha 3, coluna 6)?
Details
Estamos considerando que começamos a contar as linhas e colunas do zero. A posição do vetor é 19. Este número é obtido pela expressão
i * c + j
ié a linha a ser acessadajé a colunacé o número de colunas da matriz
19 = 2 * 7 + 5
Tip
Conseguimos redimensionar um vetor usando o método resize, que recebe o novo número de elementos do vetor.
Example
Faça uma terceira versão de calcula_distancias, desta vez usando o layout de memória acima. Verifique que o programa continua retornando os mesmos resultados que as versões anteriores.
Question
Rode novamente os testes de profiling e verifique o número de instruções para esta nova versão. Compare este valor com os anteriores e comente.