Análise dos resultados obtidos com DQN
Na aula passada implementamos uma versão simples do Deep Q-Learning para o ambiente LunarLander-v3 e comparamos os resultados com a implementação do algoritmo DQN, também implementado em sala de aula. Ao comparar os resultados obtidos com DQN e Deep Q-Learning, esperamos uma curva de apresendizado similar a apresentada abaixo:
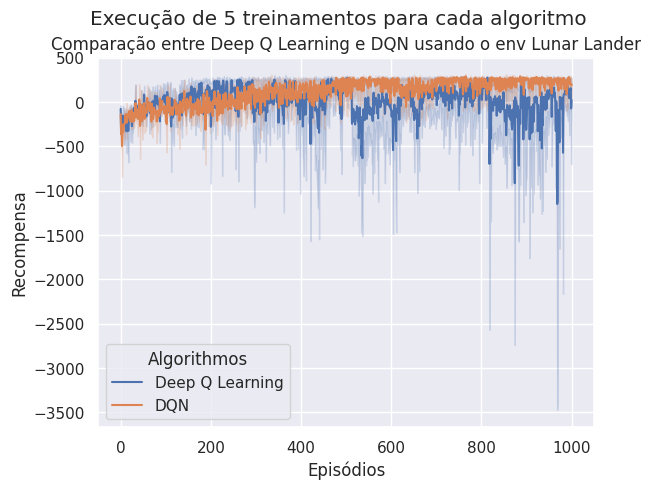
Estas curvas de aprendizado foram obtidas utilizados os seguintes hiperparâmetros:
gamma = 0.99
epsilon = 1.0
epsilon_min = 0.01
epsilon_dec = 0.99
episodes = 1000
batch_size = 64
learning_rate=0.001
memory = deque(maxlen=10000)
ma_steps = 1500
A arquitetura da rede neural utilizada foi a mesma para ambos os algoritmos:
model = Sequential()
model.add(Dense(512, activation=relu, input_dim=env.observation_space.shape[0]))
model.add(Dense(256, activation=relu))
model.add(Dense(env.action_space.n, activation=linear))
Foram executados 5 treinamentos para cada algoritmo.
Com os resultados obtidos, percebemos que o DQN é mais estável que o Deep Q-Learning. De acordo com a literatura, o DQN além de mais estável também converge mais rápido que o Deep Q-Learning.
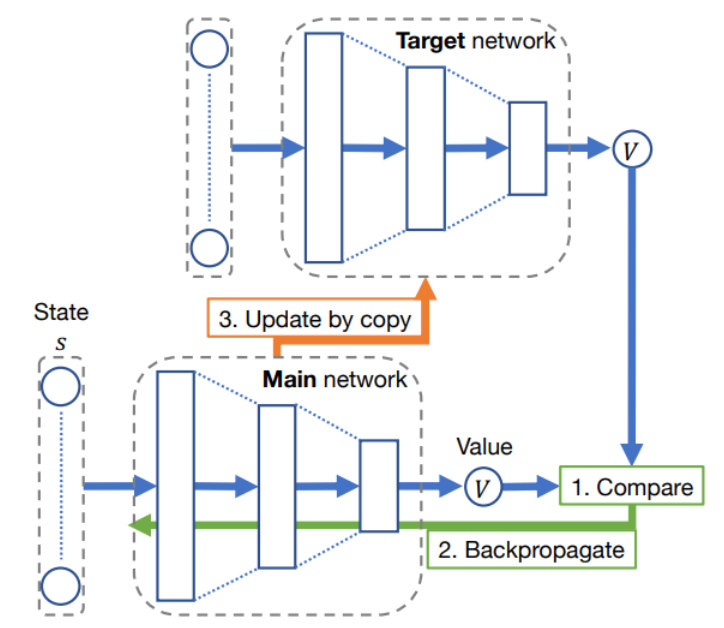
O DQN é mais estável porque utiliza duas redes neurais: uma para estimar a função de valor e outra para calcular a recompensa acumulada. Além disso, também faz uso do conceito de experience replay. A imagem abaixo sumariza a relação entre as duas redes neurais: