Aula 3: Atributos Categóricos#
Objetivo da aula: Ao fim desta aula, o aluno será capaz de operar com atributos categóricos para encontrar segmentações do dataset.
Nesta aula, trabalharemos com dados de clientes do iFood. Esses dados foram disponibilizados pelo próprio iFood, e fazem (ou, ao menos, faziam) parte da dinâmica de contratação de pessoas para a equipe de análise de dados da empresa.
Dicionário de dados: download
Texto introdutório#
Hoje em dia, é comum que empresas tenham dados de seus clientes. Esses dados servem para associar características como a renda ou a situação familiar ao comportamento dos clientes. O objetivo final dessa associação é tentar antecipar as compras que são potencialmente feitas por clientes de determinadas categorias, de forma a guiar ações de marketing como a exibição de propagandas ou a personalização de ofertas.
É possível usar Machine Learning para encontrar automaticamente essas associações, mas algoritmos de aprendizado automático podem encontrar viéses ou coincidências nos bancos de dados. Isso pode levar a situações indesejáveis, como a propagação de preconceitos. Além disso, algoritmos de aprendizado são tipicamente caixa-preta, isto é, são difíceis de explicar, o que impede que seus resultados sejam auditáveis e, portanto, torna-os pouco efetivos em ambientes em que alguém deve ser responsabilizado pelos resultados gerados.
Por isso, ainda é importante encontrar segmentos de bancos de dados e aprender com eles. Esse segmento que é escolhido manualmente para fazer alguma análise é chamado de recorte. Por exemplo, podemos separar clientes casados de clientes solteiros, e essas categorias compõem nosso recorte.
Nesta atividade, faremos recortes para descobrir características de clientes do iFood.
Exercício 1#
Objetivo: ler a base de dados e interpretar suas colunas
O código abaixo lê os dados do dataset do iFood. Após confirmar que a leitura funciona, procure no site-fonte dos dados uma explicação sobre o conteúdo de cada coluna. O que cada coluna significa?
import pandas as pd
df = pd.read_csv('dados/iFood/ml_project1_data.csv')
df.head()
| ID | Year_Birth | Education | Marital_Status | Income | Kidhome | Teenhome | Dt_Customer | Recency | MntWines | ... | NumWebVisitsMonth | AcceptedCmp3 | AcceptedCmp4 | AcceptedCmp5 | AcceptedCmp1 | AcceptedCmp2 | Complain | Z_CostContact | Z_Revenue | Response | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5524 | 1957 | Graduation | Single | 58138.0 | 0 | 0 | 2012-09-04 | 58 | 635 | ... | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 1 |
| 1 | 2174 | 1954 | Graduation | Single | 46344.0 | 1 | 1 | 2014-03-08 | 38 | 11 | ... | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 2 | 4141 | 1965 | Graduation | Together | 71613.0 | 0 | 0 | 2013-08-21 | 26 | 426 | ... | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 3 | 6182 | 1984 | Graduation | Together | 26646.0 | 1 | 0 | 2014-02-10 | 26 | 11 | ... | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
| 4 | 5324 | 1981 | PhD | Married | 58293.0 | 1 | 0 | 2014-01-19 | 94 | 173 | ... | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 11 | 0 |
5 rows × 29 columns
Exercício 2#
Objetivo: contar variáveis categóricas no dataset para caracterizar os seus elementos
O código abaixo mostra como contar o número de ocorrências de cada categoria em uma coluna de um dataframe.
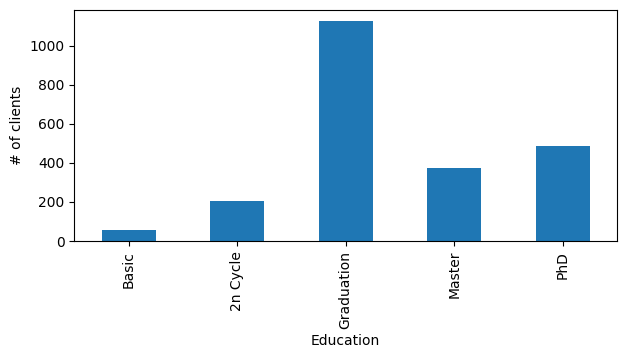
Qual é o nível educacional da maior parte dos clientes?
Modifique o código para descobrir quantos clientes da base de dados são casados.
Analisando a informação de estado civil dos clientes, você acredita que alguns dados podem não ser confiáveis? Caso afirmativo, remova-os do dataframe.
edu = df.value_counts('Education')
print(edu)
Education
Graduation 1127
PhD 486
Master 370
2n Cycle 203
Basic 54
dtype: int64
Exercício 3#
Ordenar colunas categóricas para evidenciar que tratam-se de níveis de uma progressão
Embora a “educação” seja uma variável categórica (uma vez que não tem valores numéricos), existe uma ordenação inerente às categorias. Podemos informar ao Pandas qual é essa ordenação usando o código abaixo.
A ordenação das categorias foi informada manualmente. Seria possível, neste caso específico, automatizar completamente o processo? Por que?
Por que é necessário informar o parâmetro
sort=Falsena chamada devalue_counts?Modifique o código para passar a mostrar o estado civil (marital status) dos usuários. Neste caso, a ordenação ainda faz sentido?
df['Education'] = pd.Categorical(df['Education'], ["Basic", "2n Cycle", "Graduation", "Master", "PhD"])
edu = df.value_counts('Education', sort=False)
print(edu)
Education
Basic 54
2n Cycle 203
Graduation 1127
Master 370
PhD 486
dtype: int64
Exercício 4#
Mostrar a contagem de variáveis categóricas em plots de barras
O código abaixo mostra como mostrar as contagens que calculamos em um gráfico de barras.
“Gráfico de barras” é o mesmo que “histograma”? Por que?
Modifique a chamada do gráfico para passar a mostrar as contagens de clientes de acordo com o estado civil.
import matplotlib.pyplot as plt
plt.style.use('default')
#import seaborn as sns
#sns.barplot(x=edu.index, y=edu, color='b')
edu.plot.bar(figsize=(7,3))
plt.ylabel('# of clients')
plt.xlabel('Education')
plt.show()
Exercício 5#
Objetivo: fazer contagens usando duas variáveis categóricas simultaneamente
A função crosstab do Pandas cria uma tabela relacionando contagens de duas variáveis categóricas.
O que significa cada elemento da tabela que foi criada?
O parâmetro
normalizepode receber os valoresFalse,True,indexoucolumns. O que cada um deles significa?Um cliente típico do iFood tem que combinação de nível de educação e estado civil?
df_ = pd.crosstab(index=df['Education'], columns=df['Marital_Status'])
print(df_)
Marital_Status Absurd Alone Divorced Married Single Together Widow \
Education
Basic 0 0 1 20 18 14 1
2n Cycle 0 0 23 81 37 57 5
Graduation 1 1 119 433 252 286 35
Master 1 1 37 138 75 106 12
PhD 0 1 52 192 98 117 24
Marital_Status YOLO
Education
Basic 0
2n Cycle 0
Graduation 0
Master 0
PhD 2
Exercício 6#
Objetivo: analisar duas propostas de gráficos de barras para mostrar dados
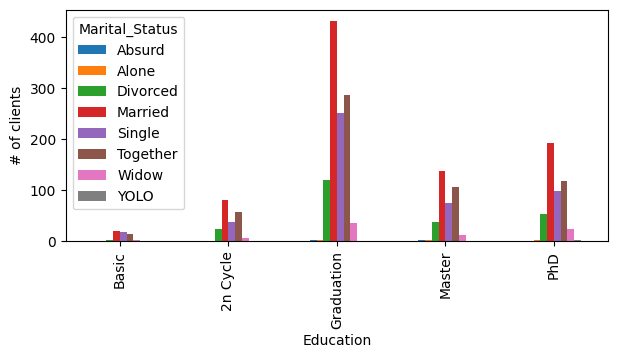
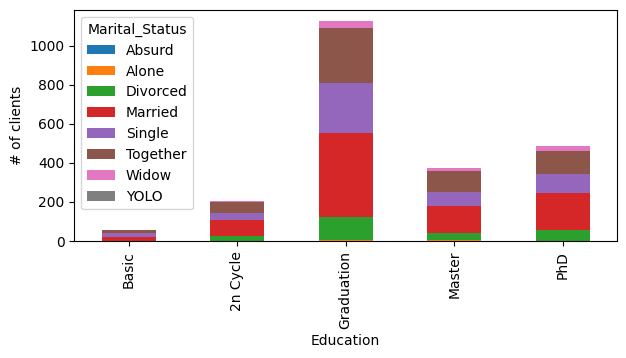
No código abaixo, temos duas propostas de códigos de barras: um com barras lado-a-lado e outro com barras empilhadas.
As cores das barras, suas larguras e suas cores estão permitindo uma boa visualização dos dados? Consulte a documentação e modifique os parâmetros que achar necessário.
Que informações podemos ver no gráfico lado-a-lado que é mais difícil visualizar no gráfico de barras empilhadas?
Que informações podemos ver no gráfico empilhado que é mais difícil visualizar no gráfico de barras lado-a-lado?
df_.plot.bar(stacked=False, figsize=(7,3))
plt.ylabel('# of clients')
plt.xlabel('Education')
plt.show()
df_.plot.bar(stacked=True, figsize=(7,3))
plt.ylabel('# of clients')
plt.xlabel('Education')
plt.show()
Exercício 7#
Objetivo: ler e entender documentação do Pandas. Transpor um dataframe e visualizar os resultados
O método transpose() inverte as linhas e colunas de um dataframe. Consulte a documentação do método e use-o para mostrar um gráfico de barras que evidencie os níveis educacionais de clientes casados, solteiros e divorciados.
# Espaço para resolver o exercício 7
Exercício 8#
Objetivo: mostrar dados bi-dimensionais em uma figura
Faz parte do senso comum pensar que, quanto maior o nível educacional de uma pessoa, maior será sua renda.
Faça uma figura que responda à pergunta: “na base de clientes do iFood, pessoas de nível educacional maior têm a renda maior?”
Usando as técnicas que aprendemos hoje, faça uma figura que evidencie a resposta à sua pergunta.
Não esqueça de rotular eixos e colocar título na figura! No título, tanto a pergunta quanto a resposta devem ficar evidentes.
# Espaço para resolver o exercício 8